

Hakuna Ma-Data: Identify Wildlife on the Serengeti¶

Camera traps are an invaluable tool in conservation research, but the sheer amount of data they generate presents a huge barrier to using them effectively. This is where AI can help!
In the Hakuna Ma-Data Challenge, participants built models to tag species from a new trove of camera trap imagery provided by the Snapshot Serengeti project. To power more accurate and generalizable models, this competition featured over five terabytes of data—2.65 million sequences of camera trap images, totaling over 7 million images—for training and testing species tagging models.
But that's not all! This was a new kind of DrivenData challenge, where competitors packaged everything needed to do inference and submitted that for containerized execution on Azure. By leveraging Microsoft Azure's cloud computing platform and Docker containers, the competition infrastructure moved one step closer to translating participants’ innovation into impact.
Participants were given ten seasons of publicly available Snapshot Serengeti data to use for training their models. Our containerized execution approach allowed us to evaluate competitors' models on data that participants never saw during the competition, specifically never-before-released data from Season 11.
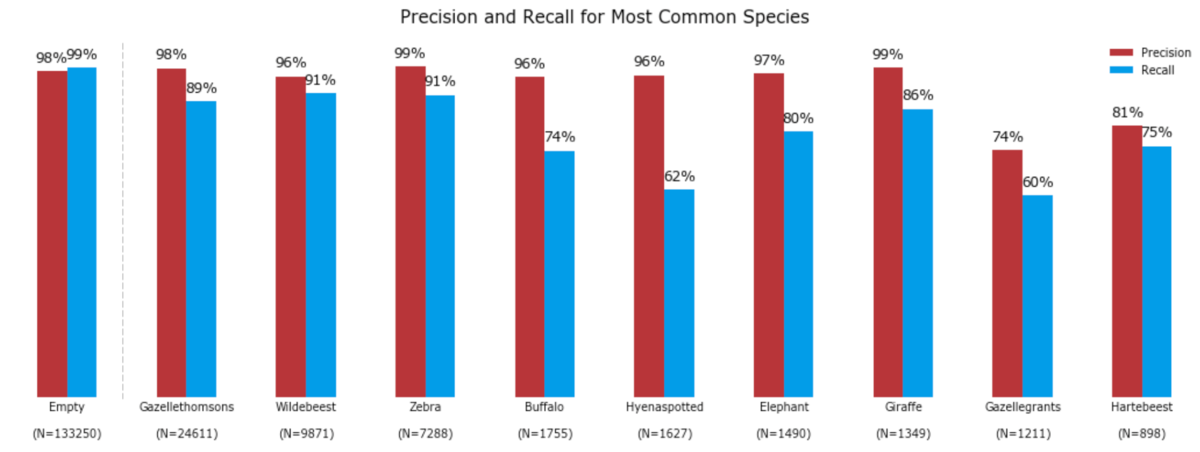
This was no easy feat! Yet we saw more than 800 participants generate 550 submissions over the two month competition! The top 25 finalists had their best submissions--evaluated on a subset of the withheld Season 11 images--run against the entire Season 11 test set. The final winners held their spots atop the leaderboard, achieving on the entirely withheld season of data:
- 97% accuracy in identifying blank image sequences (71% of image sequences were blank)
- 86% accuracy in identifying the species in non-blank image sequences (meaning the species with the highest predicted probability was indeed in the image)
- for the 1% of sequences that had two species, correctly identified both of them 33% of the time
Congrats to Team ValAn_picekl for creating the winning model! This and all the other prize-winning solutions are linked below and made available under an open source license for anyone to use and learn from. Meet the winners below and get a snapshot of their leaderboard-topping wildlife-spotting approaches!
Meet the winners¶
Miroslav Valen and Lukas Picek (Team ValAn_picekl)¶

|

|
Place: 1st
Prize: $12,000
Hometown: Stockholm, Sweden and Rokycany, Czech Republic
Background:
Miroslav Valan: I pursued a degree of doctor of veterinary medicine and later I obtained a PhD in the same field. In the meantime, I fell in love with computer vision and AI in general and made a huge professional stride.
Lukas Picek: Workaholic. Addicted to Computer Vision Challenges. PhD student with focus on FGVC (Fine-Grained-Visual-Categorization). Experienced team leader from industry. Startup Founder.
Summary of approach:
As execution time was limited and we joined the competition really late with limited resources, we decided to use lightweight convolutional neural network architectures with one exception. Key models were EfficientNet B1 and EfficientNet B3, and SE-ResNext50. For all mentioned architectures we used ImageNet pretrained checkpoints.
- https://pytorch.org/docs/stable/torchvision/models.html
- https://github.com/Cadene/pretrained-models.pytorch
- https://github.com/lukemelas/EfficientNet-PyTorch
While training we used cyclical learning rates / one cycle policy (see https://arxiv.org/pdf/1708.07120.pdf and https://arxiv.org/pdf/1506.01186.pdf), warm start and cosine annealing, a consistent input size of 512x384, horizontal flip data augmentation, and no validation set. We also used both random sampling and chunk sampling (where the training set was divided in chunks comprised of one or more seasons). For inference, we used a weighted ensemble with six forward passes in total.
- EfficientNet B1 (chunks)
- EfficientNet B3 (random)
- SE-ResNext50 (random) + horizontal flip
- SE-ResNext50 (chunks) - 2 checkpoint (after season 10 and 9)
To get to the sequence level, we took the mean for animals and geometric mean for empty.
They also noted: Zeeeeeebra image motivated us to commit to the task!
Check out Team ValAn_picekl's full write-up and solution in the competition repo.
Artur Kuzin¶

Place: 2nd
Prize: $6,000
Hometown: Moscow, Russia
Username: n01z3
Background:
I’m working as Head of Computer Vision at X5 Retail (Group Largest multi-format retailer in Russia). Also Kaggle Grandmaster (rank 7). I am leading a team of 15 CV engineers and developers. Tasks that the team cover both R&D in the ML and CV domains as well as envelop the whole solution from shaping hardware architecture to integration with the data warehouse.
For more check out Artur's interview in HackerNoon
Summary of approach:
I used a dataset from Pavel Pleskov, which was reduced to a width of 512. He used PIL and ANTIALIAS interpolation.
- swsl_resnext50, wsl_resnext101d8. The first convolution and the first batch normalization are frozen during all stages of training.
- pytorch-lightning, apex O1, distributed
- WarmUp, CosineDecay, initLR 0.005, SGD, WD 0.0001, 8 GPUs, Batch 256 per GPU
- Loss / metric
torch.nn.MultiLabelSoftMarginLoss - Progressive increase in size during training. Width resize: 256 -> 320 -> 480 for resnext50; 296 -> 360 for resnext101
- During training, resize to ResizeCrop size for the width -> RandomCrop with ResizeCrop / 1.14 size. Moreover, the crop is not square, but rectangular with the proportion of the original image. During inference, resize to ResizeCrop and that’s it.
- From augmentations: flip, contrast, brightness. With default parameters from albumentations.
- Test-time augmentation (TTA): flip
- Averaging within one series: geometric mean
- TTA prediction and model averaging: geometric mean
Check out n01z3's full write-up and solution in the competition repo.
Or, watch Artur's presentation on his solution from the ODS.ai meetup.
Ivan Bragin¶

Place: 3rd
Prize: $2,000
Hometown: Voronezh, Russia
Username: bragin
Background:
Most of my experience (about 5 years) is development of high load services using such technologies as Hadoop, Spark, Cassadra, Kafka. Last 2 years I work as a CV engineer for embedded devices in noema.tech.
Summary of approach:
- Reproduced baseline.
- Changed model, trainable layers, amount of images. Changed loss function to the metric function.
- Found the InceptionResNetV2 model, which gave me the best score, from https://keras.io/applications/.
- After training several models and creating an ensemble, looked at the losses of each class and found that empty was the biggest.
- Extracted the background from sequences of images and trained a binary classifier (empty/ non-empty).
- Trained lgbm classifier as a second level model using predictions of each image + prediction of background classifier.
- Build merged DNN based on InceptionResNetV2 which takes background and mean of images simultaneously.
- Updated lgbm classifier using all model that I trained before.
DNNs trained on seasons 1-8 (9,10 for validation), lgbm trained jn season 9 (10 for validation).
Check out bragin’s full write-up and solution in the competition repo.
Thanks to all the participants and to our winners! Special thanks to Microsoft AI for Earth for enabling this fascinating challenge and to Snapshot Serengeti for providing the data to make it possible!
















{kind=link}