How to estimate surface-level NO2 using OMI column NO2 data¶
Welcome to the getting started notebook for the trace gas track of the NASA Airathon: Predict Air Quality challenge! The goal of this tutorial is to provide some helpful pointers and starter code to ingest, preprocess, explore, and work with one of the atmospheric data products derived from the Ozone Monitoring Instrument (OMI) onboard the Aura satellite. The specific scientific parameter covered by this tutorial is Tropospheric Column Nitrogen Dioxide (NO2), made available in Hierarchical Data Format (HDF). If OMI, NO2, or HDF are new concepts to you, then read on!
Before getting started, check out the Airathon competition homepage to learn more about the goal of this important challenge. In this tutorial, we'll:
- Provide an overview of some key concepts
- Explore the competition metadata
- Demonstrate how to load data in HDF5
- Clean and align OMI data
- Build a rudimentary model to predict trace gas levels
Let's get started!
The Data¶
What is OMI?¶
Aura is a multi-national NASA scientific research satellite that orbits the Earth to study Earth's ozone layer, air quality, and climate. Launched in 2004, it passes from south to north over the equator in the afternoon and is a member of a constellation of satellites with different science objectives that fly in close proximity known as the "A-Train". Their orbits are sun-synchronous, meaning that they pass the equator at the same local solar time on every orbit.
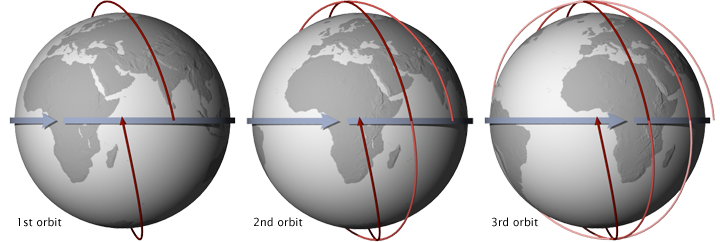
OMI is the name of a remote sensing instrument administered by NASA aboard the Aura satellite. This down-looking instrument measures backscattered sunlight in the visible and ultraviolet wavelengths and captures most of the Earth's surface each day. It tracks pollutants that threaten human health and agricultural productivity, and has ability to distinguish between aerosol types, such as smoke, dust, and sulfates. OMI can also measure cloud pressure and coverage, which are used to derive ozone. Sophisticated retrieval algorithms are used to convert measured radiation to pollution concentrations.
This exercise will focus on the OMNO2d Version 3 gridded 0.25 degree x 0.25 degree Level 3 product, which is pre-approved for the competition. Level 3 products represent values that have been filtered, pre-processed, and aggregated across different dates or footprints. 0.25 degree x 0.25 degree represents the resolution.
What is Tropospheric Column NO2?¶
OMNO2d reports Total and Tropospheric Column NO2. Nitrogen dioxide (NO2) is a harmful pollutant produced during combustion. According to NASA, it has been designated as a criteria pollutant by the U.S. Environmental Protection Agency (EPA) because of its negative effects on human health and the environment. Vertical column density (VCD) refers to the number of molecules between a remote sensing instrument and the Earth's surface. For NO2, the amount high in the atmosphere (in the stratosphere) is often removed to derive the column in the lower part of the atmosphere (in the troposphere), known as Tropospheric Vertical Column Density (TVCD). VCD and TVCD are typically measured in molecules of NO2 per square centimeter, and may be divided by 1015 for readability. These column densities have been found to be helpful for estimating surface-level NO2 levels.

While the OMNO2d data product contains a variety of data fields, we will focus on ColumnAmountNO2Trop. You are encouraged to explore and leverage all of the data fields made available by this data product using the OMI Data User's Guide.
Data loading¶
What's in our metadata?¶
First, let's organize our local repository using Cookiecutter Datascience and download the grid_metadata.csv, no2_satellite_metadata.csv, submission_format.csv, and train_labels.csv files from the data download page to our data/raw folder.
$ tree data/
data/
├── external
├── interim
├── processed
└── raw
├── grid_metadata.csv
├── no2_satellite_metadata.csv
├── submission_format.csv
└── train_labels.csv
4 directories, 4 filesNext, let's import some handy tools for working with geospatial data and load the metadata to see what we have.
from pathlib import Path
import random
from typing import Dict, List, Optional
import warnings
from cloudpathlib import S3Path
import geopandas as gpd
import pandas as pd
import rasterio
DATA_PATH = Path.cwd().parent / "data"
RAW = DATA_PATH / "raw"
INTERIM = DATA_PATH / "interim"
warnings.simplefilter(action="ignore", category=UserWarning)
no2_md = pd.read_csv(
RAW / "no2_satellite_metadata.csv",
parse_dates=["time_start", "time_end"],
index_col=0,
)
grid_md = pd.read_csv(RAW / "grid_metadata.csv", index_col=0)
Satellite metadata¶
Our trace gas track satellite metadata file contains information about OMI and TROPOMI data made available for model training and testing. Let's create and inspect a subset of the OMI training data.
no2_md.columns
no2_md["split"].value_counts()
no2_md["product"].value_counts()
omi_md = no2_md[(no2_md["product"] == "omi") & (no2_md["split"] == "train")].copy()
omi_md.shape
omi_md.head(3)
As OMI sweeps along an orbit, it collects data that is sectioned into pieces called granules. Each OMI granule contains Total Column NO2 and Total Tropospheric Column NO2 for all atmospheric conditions and for sky conditions where cloud fraction is less than 30 percent across each pixel. A single granule has a size of 720 x 1440 pixels. Each granule is identified by a unique granule_id with the following naming convention: {time_end}_{product}_{location}_{number}.hdf, where time_end is formatted as YYYYMMDDHHmmss. When locations and times have more than one associated file, this is denoted by number. For additional information about each of these fields, check out the NO2 data download instructions.
We can see that there are 671 OMI files to use for training. Each file covers the Los Angeles South Coast Air Basin, Delhi, and Taipei, denoted by dl-la-tpe.
Let's take a look at the time distribution in our training data.
omi_md.time_end.dt.year.value_counts()
omi_md.time_end.dt.month.value_counts().sort_index()
We have a roughly balanced distribution of files across years (2019-2020) and months, with the fewest granules from the months of November and December.
Note that a single granule contains data that was captured within a 24 hour time window. For each location, OMI makes its observations mid-day.
Grid metadata¶
Next, let's take a look our grid cell metadata.
grid_md.head(3)
grid_md.shape
grid_md.location.value_counts()
Each grid cell has a 5-character alphanumeric grid_id that uniquely identifies a 5 x 5 km grid cell and is associated with an observation in our train or test set. This file also contains important location and timezone (tz) information that can be used to localize dates, along with the polygonal coordinates of the grid cell. There is metadata available for 68 grid cells.
How do I load a OMI HDF5 file?¶
Our OMI data is stored in a HDF5 file format. At its lowest level, Hierarchical Data Format (HDF) is a set of file formats (HDF4 and HDF5) designed to store and organize large amounts of scientific data. HDF5 is the newer version of the format and is actively supported by a non-profit corporation called The HDF Group. This file format supports different data models, including multidimensional arrays, raster images, and tables. A single HDF file can hold a mix of related objects that can be accessed as a group or as individual objects.
In Python, we can read in HDF5 files using one of three libraries:
For this example, we'll be using h5py and code adapted from a script on the HDFEOS zoo.
The File module of the h5py package supports scientific datasets. Let's import this module along with some helpful tools to get started.
import os
import re
from h5py import File
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import pyproj
mpl.rcParams["figure.dpi"] = 100
The OMI metadata file contains the locations of each OMI HDF5 file on s3. We can use the S3Path class from the cloudpathlib package to generate a path to a sample data file.
filepath = S3Path(omi_md.iloc[0].us_url)
filepath
To read this file, we can instantiate a File object using a string representation of our path. Note that calling fspath downloads the file locally to a temporary directory.
hdf = File(filepath.fspath, mode="r")
# List available datasets
for k, v in hdf.items():
print(f"{k}: {v}")
Groups are the container mechanism by which HDF5 files are organized. They operate somewhat like dictionaries, where "keys" (Group objects) denote names of group members and "values" (Dataset objects) are the members themselves. The NO2 data we are interested in is contained in the HDFEOS group within the hdf object.
The File.visititems method allows us to recursively visit all items in a group. Let's use this method to explore the structure of our file.
def print_structure(name, obj):
print(name)
hdf.visititems(print_structure)
Our hdf object contains four main variables listed under the Data Fields subtree:
ColumnAmountNO2: total NO2 column densityColumnAmountNO2CloudScreened: total NO2 column density where cloud fraction is less than 30%ColumnAmountNO2Trop: column density of NO2 in the tropospheric layerColumnAmountNO2TropCloudScreened: column density of NO2 in the tropospheric layer where cloud fraction is less than 30%
For more information about each of these variables, see this helpful Fact Sheet. For this tutorial, we will focus on the ColumnAmountNO2Trop variable. To access the ColumnAmountNO2Trop raw data, we can use [:] to create a copy of the dataset in memory.
trop_NO2 = hdf["HDFEOS"]["GRIDS"]["ColumnAmountNO2"]["Data Fields"]["ColumnAmountNO2Trop"]
raw_NO2 = trop_NO2[:]
raw_NO2
shape = raw_NO2.shape
shape
# Plot raw value heatmap
for_plot = raw_NO2.copy()
f, ax = plt.subplots(1, 1, figsize=(8, 3))
img = plt.imshow(for_plot, origin="lower", cmap="GnBu")
f.colorbar(img)
plt.suptitle("NO2 TVCD Raw Value Heatmap", fontsize=12);

According to our raw values, a single swath of our Tropospheric Column NO2 data contains 720 x 1440 pixels that represent averaged values across approximately 14 orbits in a single day. Given that our NO2 data covers the entire globe and our data has a resolution of 0.25 x 0.25 degrees, this shape is to be expected:
- Given latitude bounds of [-90, 90], 180 / 0.25 = 720 pixels
- Given longitude bounds of [-180, 180], 360 / 0.25 = 1440 pixels
Data processing¶
Now that we have our raw data, let's calibrate and map NO2 values to the competition grid cells.
How do I calibrate NO2 data?¶
To work with this data, we'll need to calibrate raw values by applying a set of accompanying attributes:
- remove missing data
- remove any remaining negative values
- remove the offset and multiply by the scale factor (if applicable)
- cast the data to a numpy masked array to handle missing entries
We can save these dataset attributes to a calibration dictionary using attrs on the trop_NO2 object.
# List available attributes
for k, v in trop_NO2.attrs.items():
print(f"{k}: {v}")
# Save attributes to a calibration dictionary
calibration_dict = {
"scale_factor": trop_NO2.attrs["ScaleFactor"][0],
"offset": trop_NO2.attrs["Offset"][0],
"missing_data_value": trop_NO2.attrs["_FillValue"][0],
}
calibration_dict
Scale factors and offsets are simply used to optimize data storage. In this specific case, scaling by a factor of one and adjusting by an offset of zero won't result in any changes to the values.
Missing data denotes low quality readings. This can happen for a number of reasons, including cloud cover. We'll convert missing data to nans.
def calibrate_data(data: File, calibration_dict: Dict):
"""Given an OMI dataset and calibration parameters, return a masked
array of calibrated data.
Args:
data (File): dataset in the File format (e.g. column NO2).
calibration_dict (Dict): dictionary containing, at a minimum,
`scale_factor` (float), `offset` (float),
`missing_data_value` (float).
Returns:
corrected_NO2 (np.ma.MaskedArray): masked array of calibrated data
with a fill value of nan.
"""
# Convert missing data to nan
data[data == calibration_dict["missing_data_value"]] = np.nan
# Remove negative values
data[data < 0] = np.nan
# Calibrate using offset and scale factor
data = ((data - calibration_dict["offset"]) * calibration_dict["scale_factor"]) / (
10**15
) # Divide by 10^15 for readability
# Convert to masked array
data = np.ma.masked_where(np.isnan(data), data)
data.fill_value = np.nan
return data
corrected_NO2 = calibrate_data(raw_NO2, calibration_dict)
corrected_NO2
pd.DataFrame(corrected_NO2.data.ravel(), columns=["NO2"]).describe()
How do I align NO2 data with coordinates?¶
We can now align each corrected NO2 pixel with grid coordinates. From there, we will be able to determine which NO2 readings overlap with our training grid cells.
We will follow four steps to map values in a 2-dimensional matrix to 3-dimensional "world" coordinates. This process is known as georeferencing:
- identify the original coordinate reference system (CRS) of the dataset
- define reference points on our grid
- perform any necessary reprojections of these points
- connect points to NO2 values
We can choose to use one of two georeferencing approaches: vector- or raster-based. You may choose to use one or the other based on computational performance, memory usage, and/or library preferences.
Vector data is composed of discrete geometric locations, or vertices, that define the shape of a spatial object (e.g. points, lines, or polygons). Each feature can carry multiple attributes about a location. Geospatial vector data can be used with the convenient geopandas.GeoDataFrame class.
Raster data is stored as a grid of values that are rendered on a map as pixels, where each pixel value represents an area on the Earth's surface. Raster data is useful for representing continuous surfaces at high levels of detail and for performing efficient geometric computations. Rasters are commonly saved as GeoTIFFs, which contain geographic metadata.
Vector-based approach¶
Step 1: A CRS defines the mathematical approach used to transform real locations on the Earth into a flattened map. The CRS of our data is the latitude-longitude projection called WGS 84, also known as EPSG:4326. WGS 84 is the most common CRS in the world and is a standard among GPS datasets.
Step 2: Since the OMI Level 3 NO2 product represents global data, the bounds for latitude are [-90, 90] and the bounds for longitude are [-180, 180]. Given the 0.25 x 0.25 degree resolution of the data, we can create equispaced arrays at a 0.25 interval maintaining the bounds of the latitude and longitude.
def define_coordinates(
lat_bounds: List[float], lon_bounds: List[float], resolution: List[float]
):
"""Given latitude bounds, longitude bounds, and the data product
resolution, create a meshgrid of points between bounding coordinates.
Args:
lat_bounds (List): latitude bounds as a list.
lon_bounds (List): longitude bounds as a list.
resolution (List): data resolution as a list.
Returns:
lon (np.array): x (longitude) coordinates.
lat (np.array): y (latitude) coordinates.
"""
# Interpolate points between bounds
# Add 0.125 buffer, source: OMI_L3_ColumnAmountO3.py (HDFEOS script)
lon = np.arange(lon_bounds[0], lon_bounds[1], resolution[1]) + 0.125
lat = np.arange(lat_bounds[0], lat_bounds[1], resolution[0]) + 0.125
return lon, lat
lon, lat = define_coordinates([-90, 90], [-180, 180], [0.25, 0.25])
Step 3: To determine which NO2 readings overlap with our training grid cells, we'll want to work in a consistent CRS. Luckily, the CRS of the competition grid cells is also WGS 84, so we won't need to reproject either set of coordinates.
Step 4: Finally, we can connect each NO2 value with a specific latitude and longitude by flattening our data into a GeoDataFrame of non-missing values. Each row represents a pixel value at a specific time and location. An OMI granule can contain up to 720 x 1440 rows. Our helper function, convert_array_to_df, will allow us to repeat this process for any data. Notice that we've added an additional keyword argument, total_bounds. Later on, this will allow us to optimize our operations by filtering out irrelevant points. For now, let's take a look at the entire dataset.
from pyproj import CRS
wgs84_crs = CRS.from_epsg("4326")
def convert_array_to_df(
corrected_arr: np.ma.MaskedArray,
lat: np.ndarray,
lon: np.ndarray,
granule_id: str,
total_bounds: Optional[np.ndarray] = None,
):
"""Align data values with latitude and longitude coordinates
and return a GeoDataFrame.
Args:
corrected_arr (np.ma.MaskedArray): data values for each pixel.
lat (np.ndarray): latitude for each pixel.
lon (np.ndarray): longitude for each pixel.
granule_id (str): granule name.
total_bounds (np.ndarray, optional): If provided, will filter
out points that fall outside of these bounds. Composed of
xmin, ymin, xmax, ymax.
"""
lons, lats = np.meshgrid(lon, lat)
values = {
"value": corrected_arr.data.ravel(),
"lat": lats.ravel(),
"lon": lons.ravel(),
"granule_id": [granule_id] * lons.shape[0] * lons.shape[1],
}
df = pd.DataFrame(values).dropna()
if total_bounds is not None:
x_min, y_min, x_max, y_max = total_bounds
df = df[df.lon.between(x_min, x_max) & df.lat.between(y_min, y_max)]
gdf = gpd.GeoDataFrame(df)
gdf["geometry"] = gpd.points_from_xy(gdf.lon, gdf.lat)
gdf.crs = wgs84_crs
return gdf[["granule_id", "geometry", "value"]].reset_index(drop=True)
gdf = convert_array_to_df(corrected_NO2, lat, lon, filepath.stem)
gdf.head(3)
gdf.shape
Notice that our dataframe contains over 500 thousand values. Let's plot the data using matplotlib.
def plot_gdf(gdf: gpd.GeoDataFrame):
"""Plot the Point objects contained in a GeoDataFrame.
Args:
gdf (gpd.GeoDataFrame): GeoDataFrame with, at a minimum,
columns for `orbit`, `geometry`, and `value`.
Displays a matplotlib scatterplot.
"""
f, ax = plt.subplots(1, 1, figsize=(8, 3))
img = ax.scatter(
x=gdf.geometry.x, y=gdf.geometry.y, c=gdf.value, s=0.15, alpha=1, cmap="RdYlBu_r"
)
f.colorbar(img)
plt.suptitle("Global Tropospheric Column NO2", fontsize=12)
plot_gdf(gdf)

Note that white pixels represent missing data.
Raster-based approach¶
Steps 1-3: Again, the CRS of our data is WGS 84 or EPSG:4326. Since NO2 represents global data, the bounds for latitude are [-90, 90] and the bounds for longitude are [-180, 180]. Since the CRS of the competition grid cells is WGS 84, we won't need to reproject either set of coordinates.
Step 4: We can define a matrix called an affine transformation that will allow us to transform image coordinates to real-world latitude and longitude coordinates. An affine transformation is a named tuple with elements a, b, c, d, e, f, which correspond to the elements in the matrix equation below, in which a pixel's image coordinates are x, y and its world coordinates are x', y'.
The only parameters we'll need are the bounds and resolution of our data file. We'll use rasterio.transform.from_bounds helper function to compute the matrix product of a translation and a scaling,
which is the underlying formula to calculate this transformation matrix.
def compute_affine_transform(
x0: float, x1: float, y0: float, y1: float, height: int, width: int
):
"""Given bounding coordinates and resolution, compute
the affine transformation.
Args:
x0 (float): left coordinate.
x1 (float): right coordinate.
y0 (float): top coordinate.
y1 (float): bottom coordinate.
height (int): image height.
width (int): image width.
Returns:
affine_transform (Affine): Affine transformation.
"""
affine_transform = rasterio.transform.from_bounds(
west=x0, south=y1, east=x1, north=y0, height=height, width=width
)
return affine_transform
# Compute WGS 84 affine transform
transform_wgs84 = compute_affine_transform(-180, 180, 90, -90, 720, 1440)
transform_wgs84
Putting this all together, we can write out a GeoTIFF file that holds our values, data type, missing data value, shape, and the coordinates of each point described by transform_wgs84.
# We can save our new tif to the "interim" folder
final_data = np.expand_dims(corrected_NO2.data, 0)
with INTERIM / filepath.name as f:
with rasterio.open(
fp=f,
mode="w+",
driver="GTiff",
count=final_data.shape[0],
height=final_data.shape[1],
width=final_data.shape[2],
dtype=str(final_data.dtype),
crs=wgs84_crs,
transform=transform_wgs84,
nodata=np.nan,
) as dst:
dst.write(final_data)
Note: while it may be computationally advantageous to take the raster-based approach to data alignment, you'll want to experiment with different fill values, reprojections, and resampling methods if you decide to follow a raster-based approach. This tutorial is a good starting point.
Create and save feature data¶
We now have everything we need to iterate through our training files, calibrate and align NO2 values, mask the images to the extent of our grid cell bounds, and prepare our new training features.
# Identify training OMI granule filepaths
fp = list(omi_md.us_url)
# Load training labels
train_labels = pd.read_csv(RAW / "train_labels.csv", parse_dates=["datetime"])
train_labels.rename(columns={"value": "no2"}, inplace=True)
# Identify training grid cells
gc = grid_md[grid_md.index.isin(train_labels.grid_id)].copy()
len(gc)
Our training data contains up to 66 unique grid cells. Using geopandas, we can transform our grid cell metadata into a GeoDataFrame where each observation represents a Polygon geometry.
polys = gpd.GeoSeries.from_wkt(gc.wkt, crs=wgs84_crs)
polys.name = "geometry"
polys_gdf = gpd.GeoDataFrame(polys)
polys_gdf["location"] = gc.location
Since the OMI data are sparse, it is expected that many values will not overlap our grid cells. We can use the spatial join sjoin_nearest function from geopandas to identify the nearest non-null NO2 value to each grid cell.
But first, let's do some optimization. Remember that our gdf contains nearly 500 thousand points. Because the granule covers a much larger swath of land than our geographies of interest, the vast majority of those points will be irrelevant. For each city, we can generate a bounding box using the total_bounds attribute of our grid cell GeoDataFrame. We can then filter out points outside of the bounding box with the cx GeoDataFrame method. You may have noticed that in our convert_array_to_df helper function, we added a parameter that allows us to remove points outside of location bounds. By removing these points, we can dramatically speed up spatial joins!
# Determine bounding boxes
locations = polys_gdf.location.unique()
bounds = [polys_gdf[polys_gdf.location == x].total_bounds for x in locations]
# Visualize grid cells and OMI points in LA
xmin, ymin, xmax, ymax = bounds[-1]
la_gdf = gdf.cx[xmin:xmax, ymin:ymax]
la_cells = polys_gdf[polys_gdf.location == locations[-1]]
f, ax = plt.subplots(1, 1, figsize=(8, 3))
la_gdf.plot(ax=ax, c="red", alpha=1, markersize=5)
la_cells.plot(ax=ax)
plt.suptitle("Grid cells and OMI data in LA", fontsize=12);

We're now ready to use a subset of our previously generated gdf to identify points that are close to our training grid cells in a location, such as Los Angeles, and can compute the average Tropospheric Column NO2 per cell.
gpd.sjoin_nearest(la_cells, la_gdf, how="inner").groupby("grid_id")["value"].mean().head(
3
)
It's time to pull everything together! As a reminder, we've already created the following helper functions:
calibrate_datadefine_coordinatesconvert_array_to_df
We'll add a helper function to create_calibration_dict.
from h5py import Dataset
def create_calibration_dict(data: Dataset):
"""Define calibration dictionary given a Dataset object,
which contains:
- scale factor
- offset
- missing data value
Args:
data (Dataset): dataset in the Dataset format.
Returns:
calibration_dict (Dict): dict of calibration parameters.
"""
calibration_dict = {
"scale_factor": data.attrs["ScaleFactor"][0],
"offset": data.attrs["Offset"][0],
"missing_data_value": data.attrs["_FillValue"][0],
}
return calibration_dict
As an example, we'll write a GeoDataframe that contains NO2 values for all points in our grid cells for which we have available Tropospheric Column NO2 data. To speed things up, we can parallelize this process using pqdm. Because we have granules that cover a range of times and locations, we expect the number of images per grid cell to vary.
Keep in mind, this represents just one of many approaches to using the satellite data for estimating surface-level NO2.
For example, you may choose to save out rasters cropped to the extent of the competition grid cells, compute a set of zonal statistics, or may want to include values from other datasets like ColumnAmountNO2 as additional image layers.
from pqdm.processes import pqdm
def preprocess_omi_data(
granule_path: str,
grid_cell_gdf: gpd.GeoDataFrame,
dataset_name: str,
locations: List[str],
):
"""
Given a granule s3 path and competition grid cells,
create a GDF of each intersecting point and the accompanying
dataset value (e.g. Tropospheric NO2).
Args:
granule_path (str): a path to a granule on s3.
grid_cell_gdf (gpd.GeoDataFrame): GeoDataFrame that contains,
at a minimum, a `grid_id` and `geometry` column of Polygons.
dataset_name (str): specific dataset name (e.g. "ColumnAmountNO2Trop").
locations (List[str]): location names to filter points
using bounding coordinates. Options include Taipei, Delhi,
and Los Angeles (SoCAB).
Returns:
GeoDataFrame that contains Points and associated values.
"""
# Load NO2 data
s3_path = S3Path(granule_path)
hdf = File(s3_path.fspath, mode="r")
NO2 = hdf["HDFEOS"]["GRIDS"]["ColumnAmountNO2"]["Data Fields"][dataset_name]
raw_NO2 = NO2[:]
shape = raw_NO2.shape
# Calibrate data
calibration_dict = create_calibration_dict(NO2)
corrected_NO2 = calibrate_data(raw_NO2, calibration_dict)
# Determine location bounds
bounds = [grid_cell_gdf[grid_cell_gdf.location == x].total_bounds for x in locations]
# Save values that align with granules
lon, lat = define_coordinates([-90, 90], [-180, 180], [0.25, 0.25])
dfs = []
for i, bound in enumerate(bounds):
granule_gdf = convert_array_to_df(corrected_NO2, lat, lon, s3_path.name, bound)
location_gdf = grid_cell_gdf[grid_cell_gdf.location == locations[i]]
city_df = gpd.sjoin_nearest(location_gdf, granule_gdf, how="inner")
dfs.append(city_df)
df = pd.concat(dfs)
# Clean up files
Path(s3_path.fspath).unlink()
return df.drop(columns="index_right").reset_index()
def preprocess_trop_no2(
granule_paths: List[str],
grid_cell_gdf: gpd.GeoDataFrame,
dataset_name: str,
locations: List[str],
n_jobs: int = 2,
):
"""
Given a set of granule s3 paths and competition grid cells,
parallelizes creation of GDFs containing NO2 values and points.
Args:
granule_paths (List[str]): list of paths on s3.
grid_cell_gdf (gpd.GeoDataFrame): GeoDataFrame that contains,
at a minimum, a `grid_id` and `geometry` column of Polygons.
dataset_name (str): specific dataset name (e.g. "ColumnAmountNO2Trop").
locations (List[str]): location names to filter points
using bounding coordinates. Options include Taipei, Delhi,
and Los Angeles (SoCAB).
n_jobs (int): The number of parallel processes. Defaults to 2.
Returns:
GeoDataFrame that contains Points and associated values for all granules.
"""
args = ((gp, grid_cell_gdf, dataset_name, locations) for gp in granule_paths)
results = pqdm(args, preprocess_omi_data, n_jobs=n_jobs, argument_type="args")
return pd.concat(results)
train_gdf = preprocess_trop_no2(fp, polys_gdf, "ColumnAmountNO2Trop", locations)

train_gdf.head(3)
train_gdf.shape
train_gdf describes 26,403 Tropospheric Column NO2 values near our competition training grid cells!
Simple benchmark model¶
Using train_df, let's prepare an extremely simple benchmark solution for the Airathon trace gas track.
def calculate_features(
feature_df: gpd.GeoDataFrame,
label_df: pd.DataFrame,
stage: str,
):
"""Given processed NO2 data and training labels (train) or
submission format (test), return a feature GeoDataFrame that
contain a single features for mean NO2.
Args:
feature_df (gpd.GeoDataFrame): GeoDataFrame that contains
Points and associated values.
label_df (pd.DataFrame): training labels (train) or
submission format (test).
stage (str): "train" or "test".
Returns:
full_data (gpd.GeoDataFrame): GeoDataFrame that contains `mean_no2`,
for each grid cell and datetime.
"""
# Add `day` column to `feature_df` and `label_df`
feature_df["datetime"] = pd.to_datetime(
feature_df.granule_id.str.split("_", expand=True)[0],
format="%Y%m%dT%H:%M:%S",
utc=True,
)
feature_df["day"] = feature_df.datetime.dt.date
label_df["day"] = label_df.datetime.dt.date
# Calculate average NO2 per day/grid cell for which we have feature data
avg_no2_day = (
feature_df.groupby(["day", "grid_id"])
.mean()
.reset_index()
.rename(columns={"value": "mean_no2"})
)
# Join labels/submission format with feature data
how = "inner" if stage == "train" else "left"
full_data = pd.merge(
label_df,
avg_no2_day,
how=how,
left_on=["day", "grid_id"],
right_on=["day", "grid_id"],
)
return full_data
full_data = calculate_features(train_gdf, train_labels, stage="train")
full_data.head(3)
We do not want to overstate our model's performance by overfitting to one or more dates or locations. To be sure that our method is sufficiently generalizable, let's set aside a portion of the data to validate the model. To ensure that we are not using data collected in the future to estimate prior NO2, we can subset the training data into training and validation sets using the datetime field.
# 2020 data will be held out for validation
train = full_data[full_data.datetime.dt.year <= 2019].copy()
test = full_data[full_data.datetime.dt.year > 2019].copy()
In scikit-learn, we can set up a random forest with a few lines of code.
from sklearn.ensemble import RandomForestRegressor
# Train model on train set
model = RandomForestRegressor()
model.fit(train[["mean_no2"]], train.no2)
# Compute R-squared using our holdout set
model.score(test[["mean_no2"]], test.no2)
# Refit model on entire training set
model.fit(full_data[["mean_no2"]], full_data.no2)
Finally, let's make predictions for the competition test set and save them to the submission format. To keep things simple, we'll impute missing features using the average NO2 value from the training data.
# Identify test granule s3 paths
test_md = no2_md[(no2_md["product"] == "omi") & (no2_md["split"] == "test")]
# Identify test grid cells
submission_format = pd.read_csv(RAW / "submission_format.csv", parse_dates=["datetime"])
test_gc = grid_md[grid_md.index.isin(submission_format.grid_id)]
# Process test data
test_fp = list(test_md.us_url)
# Create grid cell GeoDataFrame
test_polys = gpd.GeoSeries.from_wkt(test_gc.wkt, crs=wgs84_crs)
test_polys.name = "geometry"
test_polys_gdf = gpd.GeoDataFrame(test_polys)
test_polys_gdf["location"] = test_gc.location
# Preprocess NO2 for test granules
test_df = preprocess_trop_no2(test_fp, test_polys_gdf, "ColumnAmountNO2Trop", locations)

test_df.head(3)
# Prepare NO2 features
submission_df = calculate_features(test_df, submission_format, stage="test")
# Impute missing features using training set mean/max/min
submission_df.mean_no2.fillna(train_gdf.value.mean(), inplace=True)
submission_df.drop(columns=["day"], inplace=True)
# Make predictions using NO2 features
submission_df["preds"] = model.predict(submission_df[["mean_no2"]])
submission = submission_df[["datetime", "grid_id", "preds"]].copy()
submission.rename(columns={"preds": "value"}, inplace=True)
# Ensure submission indices match submission format
submission_format.set_index(["datetime", "grid_id"], inplace=True)
submission.set_index(["datetime", "grid_id"], inplace=True)
assert submission_format.index.equals(submission.index)
submission.head(3)
submission.describe()
Finally, we will save our submission locally.
# Save submission in the correct format
final_submission = pd.read_csv(RAW / "submission_format.csv")
final_submission["value"] = submission.reset_index().value
final_submission.to_csv((INTERIM / "submission.csv"), index=False)
We can now head to the competition submissions page and upload our submission to obtain our model's R2.

We should see an R2 of -0.1543 on the leaderboard. Now it's up to you to make improvements and increase this score! We hope this tutorial provides a helpful framework for loading and exploring the data, correcting and aligning values, and working with geospatial vector and raster data.
Head over to the challenge homepage to get started. We can't wait to see what you build!
Banner image, artist's rendering of Aura, courtesy of NASA