The Challenge¶
We rely on 3D maps for urban planning, emergency response planning, and navigation; however, our current ability to very quickly update these maps after dynamic world events is limited. The winning solutions from this challenge will help us quickly and accurately update maps by predicting scene geometry from a single oblique image. The level of detail achieved by the top models from the competition exceeded our expectations. We are excited to apply these methods for both improving map currency and increasing the fidelity of current 3D models.
Monte Turner, NGA Research Foundational GEOINT Office Director
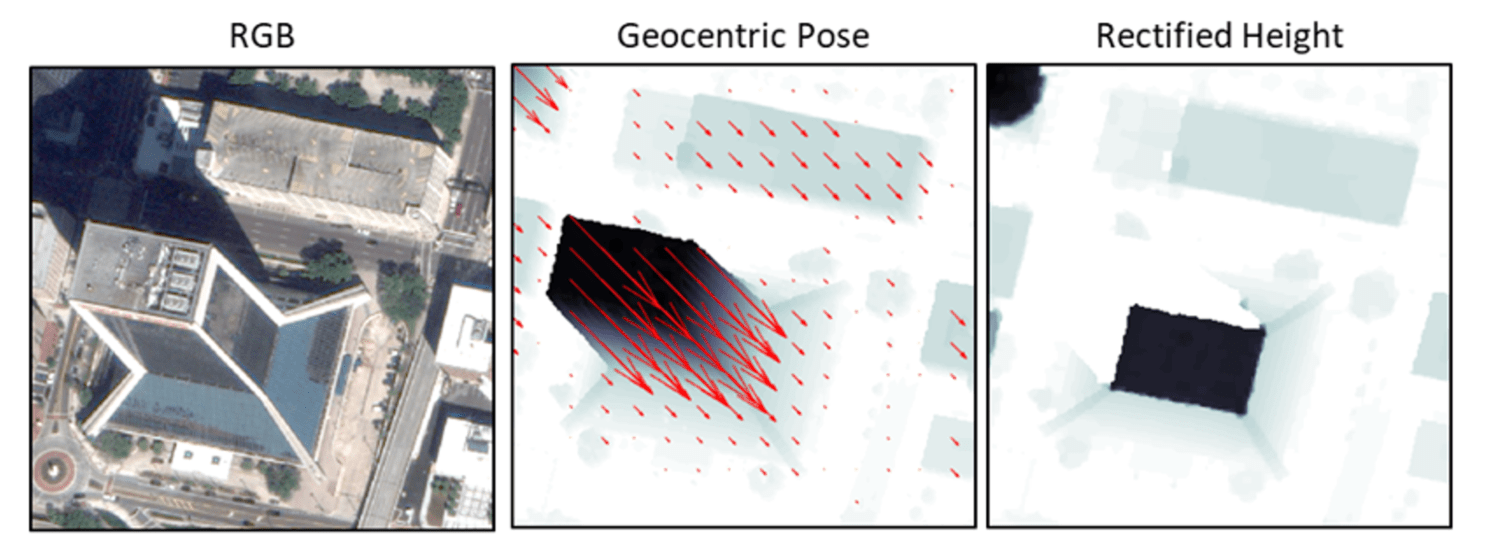
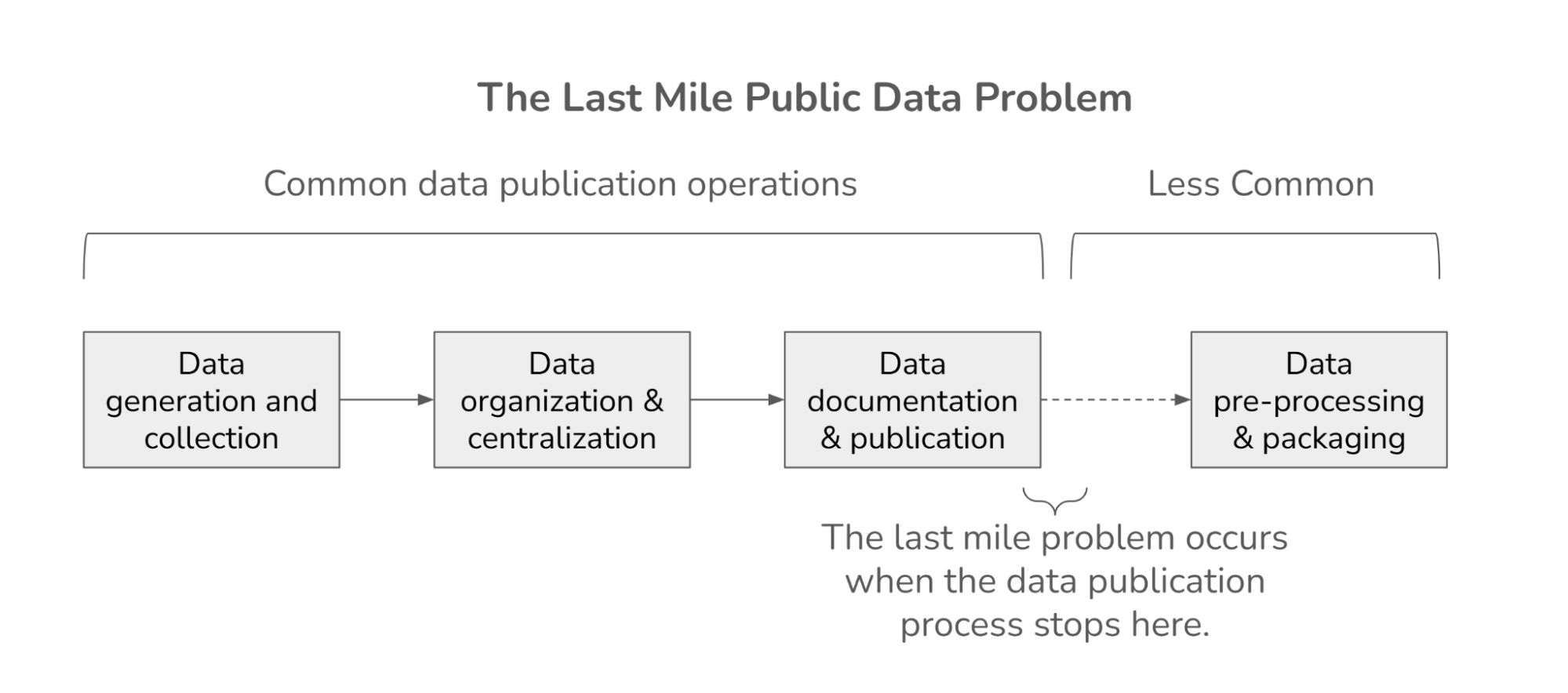
From left to right: (a) An RGB satellite image taken from an angle rather than overhead. (b) RGB image transformed into geocentric pose representation. Object height is in grayscale, and vectors for orientation to gravity are in red. (c) Rectified height of each pixel in meters based on geocentric pose. Adapted from Christie et al., “Learning Geocentric Object Pose in Oblique Monocular Images,” 2020.
Motivation¶
Overhead satellite imagery provides critical, time-sensitive information in arenas such as disaster response, navigation, and security. Most current methods for using aerial imagery assume images are taken from directly overhead, known as near-nadir. However, the first images available are often taken from an angle — they are oblique. Effects from these camera orientations complicate useful tasks such as change detection, vision-aided navigation, and map alignment.
An object’s geocentric pose, defined as the height above ground and orientation with respect to gravity, is a powerful representation of real-world structures for object detection, segmentation, and localization tasks. Recent works published at the Conference on Computer Vision and Pattern Recognition (CVPR) 2020 and CVPR Earthvision Workshop 2021 demonstrated the first methods to learn geocentric object pose from oblique monocular satellite images, with ground truth labels provided by airborne lidar. These approaches applied recent advances in single-view depth prediction to the concept of geocentric pose.
The goal of the Overhead Geopose Challenge was to transform satellite images to predict the real-world height of each pixel. The ability to accurately generate geocentric pose based on oblique monocular imagery can make early information more useful for time-sensitive applications such as disaster and emergency response.

Single-view depth prediction methods (left two images) have been very successful for practical close-range computer vision tasks. For longer range remote sensing tasks, single-view height prediction methods (right two images) have recently been proposed. Illustration is adapted from Mou and Zhu, 2018.
Results¶
At the start of the competition, DrivenData released a benchmark solution developed by the Johns Hopkins University Applied Physics Laboratory, which had a score of 0.7988. Within a week multiple participants had already beaten the benchmark! Over the course of competition, we received more than 750 submissions from participants and teams around the world.
The original benchmark was a neural network with a ResNet-34 encoder and a U-Net decoder. To evaluate submissions we used R-squared, which measures how much of the variance in the ground truth data is captured by a model. R-squared was calculated separately for each of the four cities in the dataset, and then averaged to get a final score.

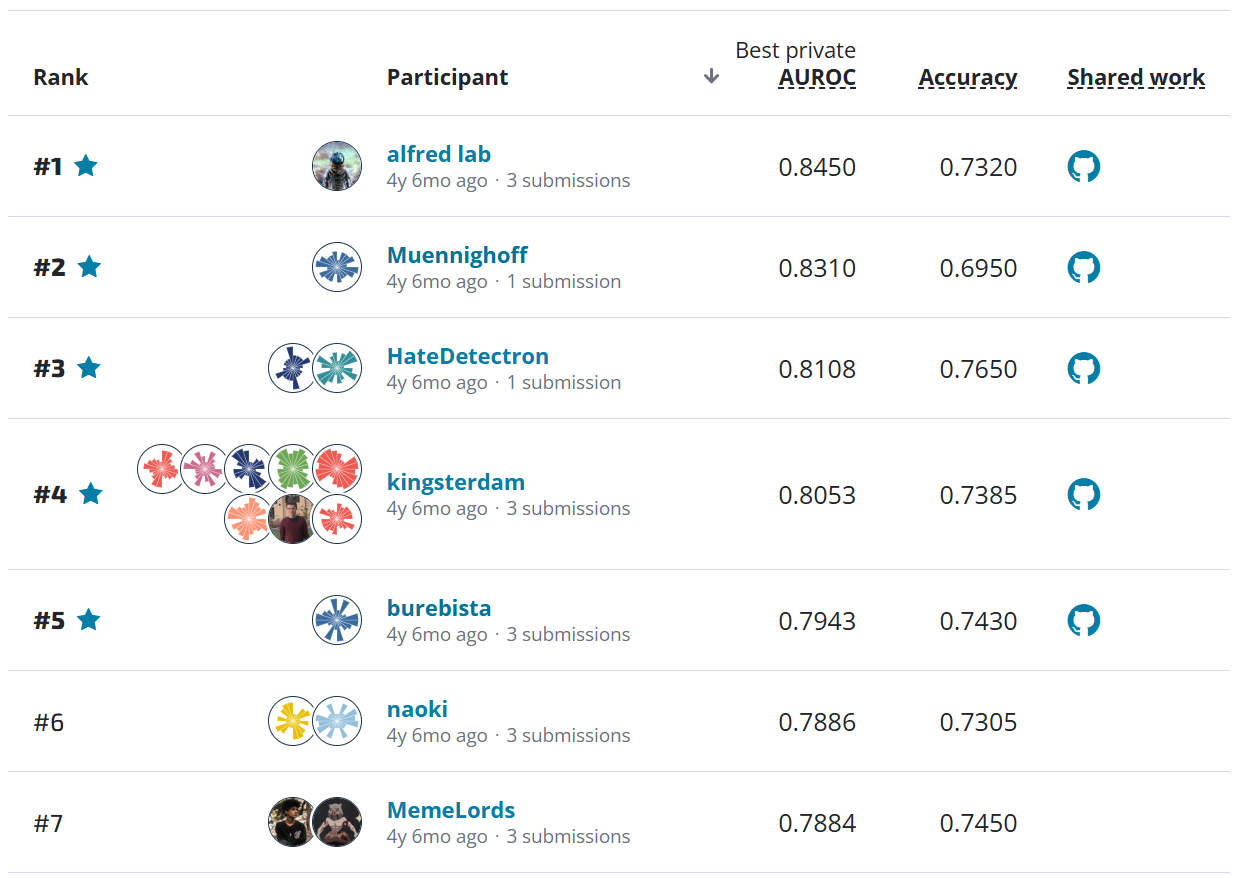
The overall results on the private leaderboard. Competitors were ranked using the average R-squared across four cities.
The benchmark struggled most with identifying unusually shaped buildings, objects where shadows were not present or misleading, and images captured from very oblique viewpoints. Additionally, tall objects are relatively rare in the data and therefore hard to train a model to identify. The geography of San Fernando, Argentina, was particularly tricky for this task because of its increased architectural diversity. All of the top participants were able to increase the R-squared for San Fernando by more than 10 percentage points!
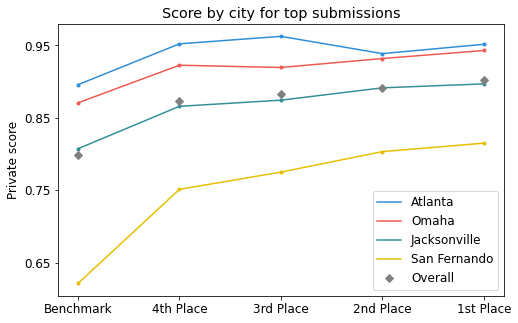
The results by city for the top four participants compared to the benchmark on the private leaderboard.
Overall, participants were able to drastically improve on the model's ability to identify small vertical features, capture object outlines with higher resolution, and correct for the most oblique viewpoints. Participants used a variety of sophisticated methods to achieve these results. A few common strategies were:
- Replacing the ResNet-34 encoder with more powerful backbones to better respond to outliers. Competitors used EfficientNets, ResNeSts, RegNetys, and more.
- Randomly cropping images during training instead of downsampling all images.
- Adjusting the loss function used during training to better account for outliers and to more closely match the competition performance metric.
- Adding custom augmentations to increase the diversity of heights and angles in the training data.
Ground truth RGB
|
Baseline prediction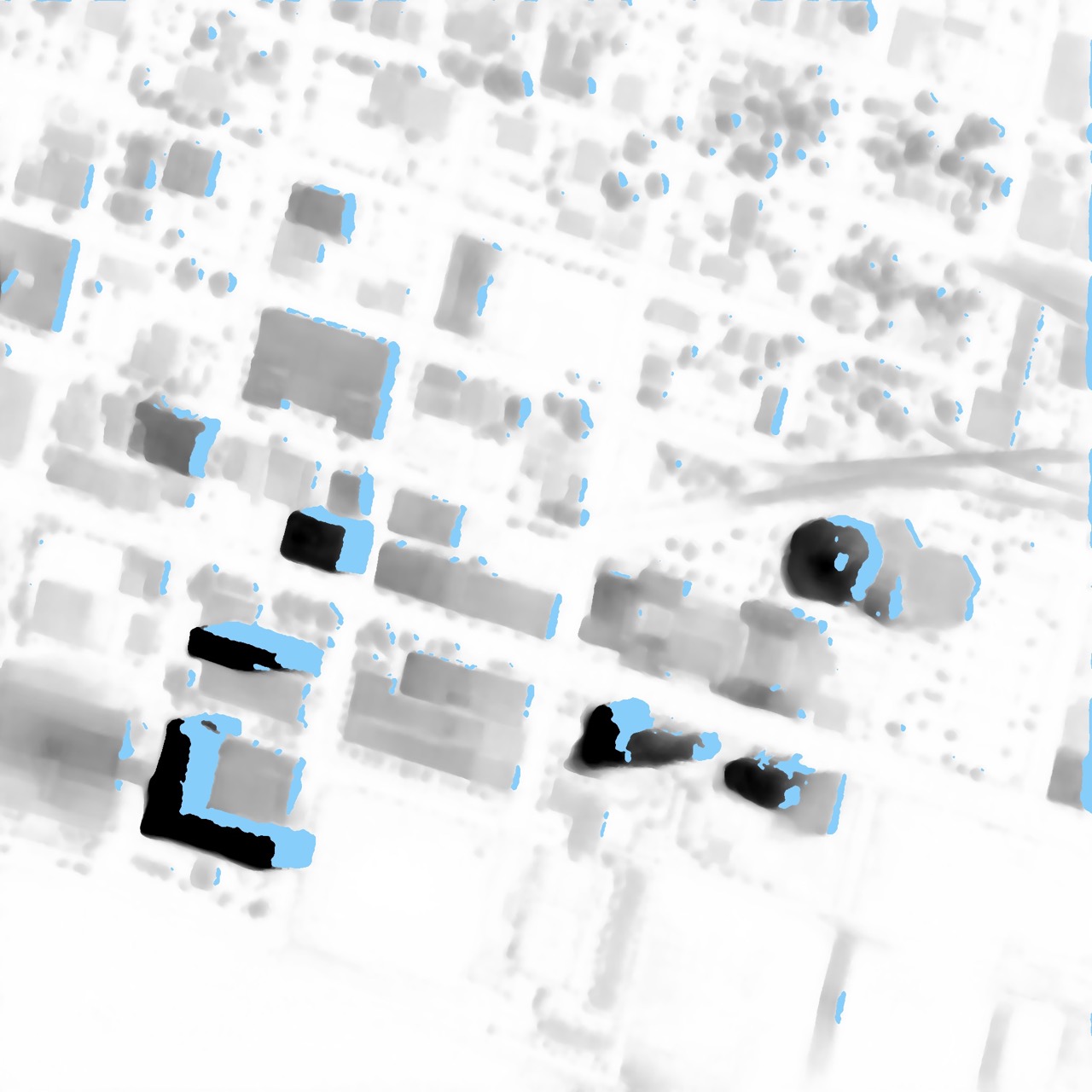
|
1st place
|
Example improvement over the baseline for image JAX_tUmuMj_AGL. Note the sharper building outlines. Images shown are from the public Urban Semantic 3D Dataset, provided courtesy of DigitalGlobe
Let's get to know our winners and how they mastered the art of geocentric pose! You can also dive into their open source solutions in the competition winners repo on Github.
Meet the winners¶
| Prize | Name |
|---|---|
| 1st place | Selim Seferbekov |
| 2nd place + Model write-up bonus | Eugene Khvedchenia |
| 3rd place | Kohei Ozaki |
| 4th place | Kirill Brodt |
| Model write-up bonus | Zhuo Zheng |
| Model write-up bonus | Igor Ivanov |
Selim Seferbekov¶

Place: 1st Place
Prize: $20,000
Hometown: Moscow, Russia
Username: selim_sef
Background
I’m a machine learning engineer at Mapbox where I often solve ML problems related to automatic map improvements. I have been participating in data science competitions for three years and consider that as my hobby.
What motivated you to compete in this challenge?
I worked with satellite/aerial imagery in a lot of challenges and at my work. Building a robust model that can work with off nadir imagery to predict building footprints is a challenging task that cannot be solved without a 3D dataset, which are usually not available. In this challenge the dataset had full information to train an end-to-end model which can transform RGB images to 3D.
Summary of Approach
While meta-architecture is mostly the same as provided baseline, there are crucial differences that allow to increase single model score by 10%.
- Encoder: I replaced Resnet34 with a very powerful encoder EfficientNet V2 L which has a huge capacity and receptive field, and is less prone to overfitting. During my experiments I also tried EfficientNet B7, which worked a bit worse, and ResneSt-200. The ResneSt-200-based model worked great on the validation split, but performance on the leaderboard was 2% worse than with EfficientNets. That led me to a conclusion that there is an implicit leak in the dataset.
- Decoder: I used a UNet-like encoder with more filters and additional convolution blocks for better handling of fine-grained details. The resolution of some images are not very high (50 cm per pixel) and pixel level details are important to obtain a high score.
- Training: Downsampling images with already low resolution (30–50 cm/pixel) will certainly harm performance so original image resolution (2048x2048) was used in training. Training on full images was not a option and I optimized a pipeline to use mixed precision training and random crops.
- Loss functions: MSE loss would produce imbalance for different cities, depending on building heights. I decided to train a model with an R2 loss for AGL/MAG outputs, which reflects the final competition metric and is also more robust to noisy training data.
Eugene Khvedchenia¶

Place: 2nd Place + Model Write-Up Bonus Award
Prize: $15,000
Hometown: Odessa, Ukraine
Username: bloodaxe
Background
At daylight I work as a computer vision research engineer. At night – I solve different machine learning competitions for the sake of fun, learning, and challenging myself. I’ve secured some good progress in competitive ML on Kaggle (Top 100), Signate (Top 1), and elsewhere. Also, I’m the author of Albumentations, an open-source image augmentation library that is de facto standard library for image augmentations in machine learning competitions, and pytorch-toolbelt, a library for quick creation of different neural network model architectures.
What motivated you to compete in this challenge?
I was curious to test my skills in finding a key to this multi-task learning problem. I had a little experience in solving dense regression problems in satellite imagery and decided to participate to check how learned best practices from semantic segmentation and object detection would help me in this competition.
Summary of Approach
In a nutshell, I’ve trained a bunch of UNet-like models and averaged their predictions. Sounds simple, yet I used quite heavy encoders (B6 and B7) and custom-made decoders to produce very accurate height map predictions at original resolution. Another crucial part of the solution was extensive data augmentation. I’ve written custom augmentation operations to augment image in RGB domain, height map, orientation, scale, and GSD consistently. I believe this technique improved model generalization capacity a lot. Another component is D4 TTA and deep ensemble for averaging predictions.
Kohei Ozaki¶

Place: 3rd Place
Prize: $6,000
Hometown: Tokyo, Japan
Username: o__@
Background
I am currently working as a software engineer in a start-up with 10 years of professional experience. I developed real-time bidding algorithms for internet advertising, developed management models for mutual funds, and analyzed insurance claims.
What motivated you to compete in this challenge?
To learn about the techniques for analyzing satellite images.
Summary of Approach
I ensembled the VFlow-UNet model using a large input resolution and a large backbone without downsampling. I used “timm-regnety_120” and “timm-resnest101e” instead of “resnet34”. Better results were obtained when the model was trained on all images from the training set. In the baseline code, the image size is downsampled from 2048x2048 to 1024x1024. Instead of that, I randomly cropped 1024x1024 images without downsampling. The test set contains images of the same location as the images in the training set. These overlaps were identified by image matching to improve the prediction results.
Kirill Brodt¶

Place: 4th Place
Prize: $3,000
Hometown: Almaty, Kazakhstan
Username: kbrodt
Background
Currently I'm doing research at the University of Montréal in computer graphics, using machine learning for problem solving: posing 3D characters via gesture drawings. I got my masters in mathematics at the Novosibirsk State University, Russia. Lately, I fell in love with machine learning, so I was enrolled in Yandex School of Data Analysis and Computer Science Center. This led me to develop and teach the first open deep learning course in Russian. Machine learning is my passion and I often take part in competitions.
What motivated you to compete in this challenge?
I like competitions and wanted to solve new problems.
Summary of Approach
The method is based on the solution provided by the authors, but in a simpler and more straightforward way: using Unet architecture with various encoders (efficientnet-b{6,7} and senet154). The model has only one above ground level (AGL) head and two heads in the bottleneck for scale and angle. The model takes a random 512x512 crop of an aerial image, the city's one hot encoding, and ground sample distance (GSD) as inputs. Then the model outputs the AGL, vector flow scale, and angle. The model is trained with mean squared error (MSE) loss function for all targets (AGL, scale, angle) using AdamW optimizer with 1e-4 learning rate. Cosine annealing scheduler with period 25 is used. To reduce the memory consumption and to speed up the training process, the model is trained in mixed precision regime with batch size 8. At inference time the model takes a full size 2048x2048 aerial image and outputs a full size AGL.
Zhuo Zheng¶

Place: Model Write-Up Bonus Award
Prize: $3,000
Hometown: Wuhan, China
Username: chuchu
Background
I am a Ph.D. student at State Key Laboratory of Information Engineering in Surveying, Mapping and Remote Sensing (LIESMARS), Wuhan University. My research interests are in remote sensing, image processing, and computer vision/earth vision, especially multi-source remote sensing imagery scene parsing. My research goal is to design original and insightful Earth vision technologies to make positive impacts on the geoscience field.
Home page: http://zhuozheng.top/
What motivated you to compete in this challenge?
I wanted to try a new task in Earth vision and promote my research.
Summary of Approach
In this challenge, we argue that the most challenging problem lies in monocular height perdition, which is caused by height variance in multi-city, radiation variance of images, and scale variance of different objects. To alleviate these problems, we first conducted an empirical upper bound analysis to locate the concrete bottlenecks of the baseline model. Motivated by these insights, we designed a high-resolution vector flow network, called HR-VFLOW, and adopted a divide-and-conquer training strategy to train this model.
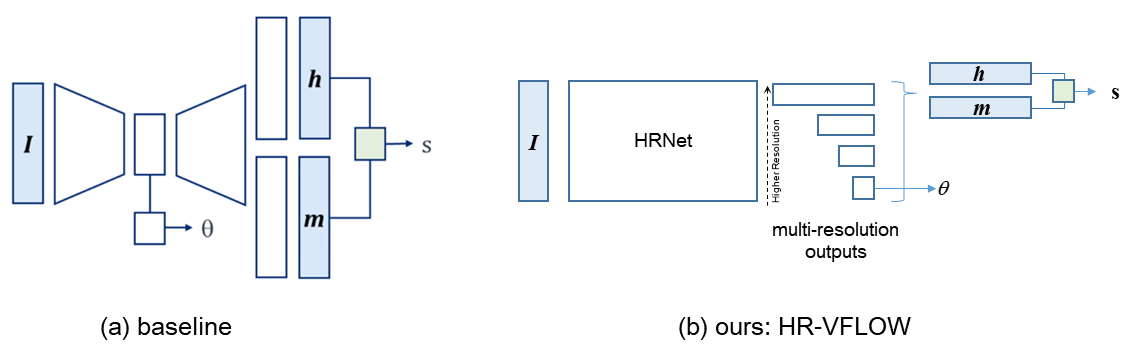
(a) The baseline model is a Unet-based model with multi-task outputs, where angle is predicted from the encoder while height and magnitude are predicted from the decoder. (b) HR-VFLOW is an HRNet-based model with multi-task outputs where the angle, height, and magnitude are all predicted from the decoder.
Overall, our final model won 5th place with an R2 of 0.8556 using single-model entry, which outperforms the baseline model by 5.6%. Our main contributions are:
- To understand the main bottlenecks of the baseline model, we conducted an empirical upper bound analysis, which suggests that the main errors are from height prediction and the rest are from angle prediction. The errors of scale prediction are very small.
- To overcome the bottlenecks, we proposed HR-VFLOW, which takes HRNet as a backbone and adopts simple multi-scale fusion as multi-task decoders to predict height, magnitude, angle, and scale simultaneously.
- Considering the height variance in the different cities, we adopted a divide-and-conquer training strategy to handle the height variance. We first pretrained our model on the whole four cities training set and then transferred the pretrained model to each specific city for better city-wise performance.
Igor Ivanov¶

Place: Model Write-Up Bonus Award
Prize: $3,000
Hometown: Dnipro, Ukraine
Username: vecxoz
Background
My name is Igor Ivanov. I'm a deep learning engineer from Dnipro, Ukraine. I specialize in CV and NLP and work at a small local startup.
What motivated you to compete in this challenge?
The problem is closely related to the segmentation task which I’m interested in. Also I really liked the introductory materials. Specifically, it was a very well written and efficient baseline model from the host team. In addition I enjoyed very detailed and informative materials about the problem and data representation made by the DrivenData team. I learned a lot from that work.
Summary of Approach
I developed a solution that reached 7th place in the private leaderboard with a score of 0.8518 which is 0.05 improvement over the baseline solution. First, I implemented training with automatic mixed precision in order to speed up training and facilitate experiments with the large architectures. Second, I implemented seven popular decoder architectures and conducted extensive preliminary research of different combinations of encoders and decoders. For the most promising combinations I ran long training for at least 200 epochs to study best possible scores and training dynamics. Third, I implemented an ensemble using weighted average for height and scale target and circular average for angle target. These approaches helped to substantially improve baseline solution. I believe that my solution and research results will be useful for further development of this task.
Thanks to all the participants and to our winners! Special thanks to the National Geospatial-Intelligence Agency and the Johns Hopkins University Applied Physics Laboratory for enabling this important and interesting challenge and for providing the data to make it possible!
Approved for public release, 21-943