Differential Privacy Temporal Map Challenge¶
Large data sets containing personally identifiable information (PII) are exceptionally valuable resources for research and policy analysis in a host of fields supporting America's First Responders such as emergency planning and epidemiology.
Temporal map data is of particular interest to the public safety community in applications such as optimizing response time and personnel placement, natural disaster response, epidemic tracking, demographic data and civic planning. However, the ability to track information related to a person's location over a period of time presents particularly serious privacy concerns.
Synthetic data, or artificial data created to resemble original records, has the ability to offer greater privacy protections than traditional anonymization techniques. Differentially private synthetic data can be shared with researchers, policy makers, and even the public without the risk of exposing individuals in the original data. Yet, the synthetic records are only useful if they preserve the trends and relationships in the original data.
The goal of the Differential Privacy Temporal Map Challenge (DeID2) is to develop algorithms that preserve data utility as much as possible while guaranteeing individual privacy is protected. The challenge features a series of coding sprints to apply differential privacy methods to temporal map data, where one individual in the data may contribute to a sequence of events.
Results from the third and final algorithm sprint are described below! For a summary of previous sprints, see the results posts from Sprint 2 (American Community Survey) and Sprint 1 (Baltimore 911 incidents).
Sprint 3: Chicago Taxi Rides¶
The Challenge¶
Sprint 3 was open to submissions from March 29 to May 15, 2021. This sprint featured records of millions of taxi trips in Chicago, adapted from the Chicago Open Data Portal.
The data included 78 map segments (the community areas where taxis departed and arrived) and 21 time segments (morning, afternoon, and night shifts for each day of the week), along with information on trip time, distance, location, payment, and service provider. The data was broken into taxi-weeks, and an individual could taxi could make up to 200 trips in a week. This meant the maximum number of records per individual was 200, significantly higher than the previous two sprints. To succeed in this competition, participants needed to build de-identification algorithms for generating synthetic, privatized taxi records that most accurately preserved the patterns in the original data.
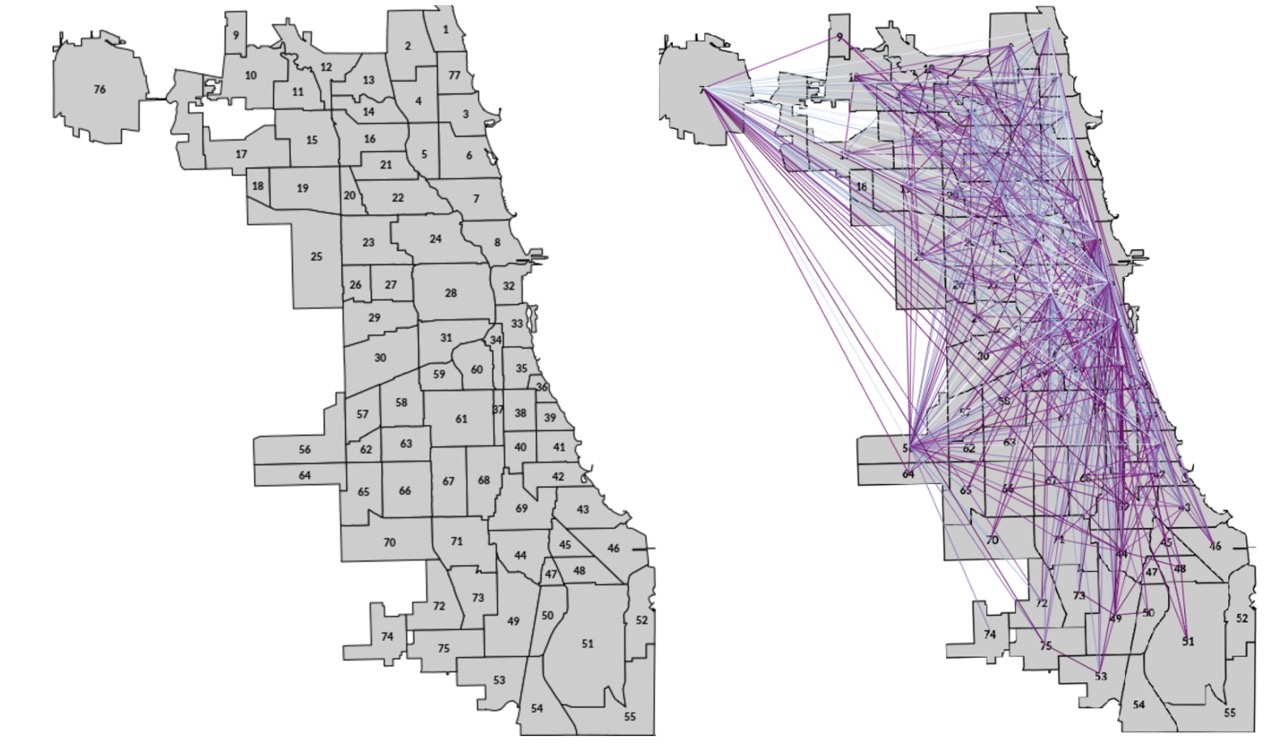
Map segments in the data included 77 Chicago community areas (along with a code for "unknown"), shown on the left. Frequent taxi trips between community areas are shown on the right. Connections between community areas was especially a focus of the second component of the accuracy scoring metric this sprint.
As always in this challenge, different areas have different populations, habits, incomes, workplaces, and other characteristics, and they’ll show up differently in the data. As approaches in this challenge were scored in every community area, successful solutions needed to preserve patterns across all communities, not just the most populated or heavily trafficked.
Meanwhile, in the data as in life, there is periodicity to the weekly grind. What is Chicago like on a typical Monday morning? A Friday night? Who’s going where (and how much are they tipping) on Wednesday at rush hour? Successful solutions also needed to preserve time patterns when generating synthetic taxi records.
To assess how well synthetic records preserved meaningful patterns like this from the original data, solutions were evaluated for data utility at different levels of guaranteed privacy (indicated by epsilon). Aspects of the scoring approach were informed by the metrics contest run as part of the broader Differential Privacy Temporal Map Challenge. In this sprint, solutions were evaluated on three different measures of utility, each contributing equally to the total score:
- K-marginal feature similarity reflected how well the distribution of trip features was preserved for each and every community area (even ones that used taxis relatively rarely).
- Graph-edge map similarity reflected how well location connections between pickup and dropoff locations were conserved.
- Individual higher-order conjunction reflected how well types of individual taxis were conserved. Did the synthetic taxi drivers have the same patterns of shift work and driving areas as the original taxis?
To produce final scores, algorithms were run on two new data sets representing taxi rides in 2016 and 2020. 2016 preceded the dramatic rise in populariy of ride sharing apps like Uber and Lyft. 2020 saw major shifts both in work and social life with COVID-19. Compared with the public data from 2019 that was provided for competitors to use while they were developing their algorithms, these final scoring data sets demanded robust solutions that could handle significant differences in data distribution.
The Results¶
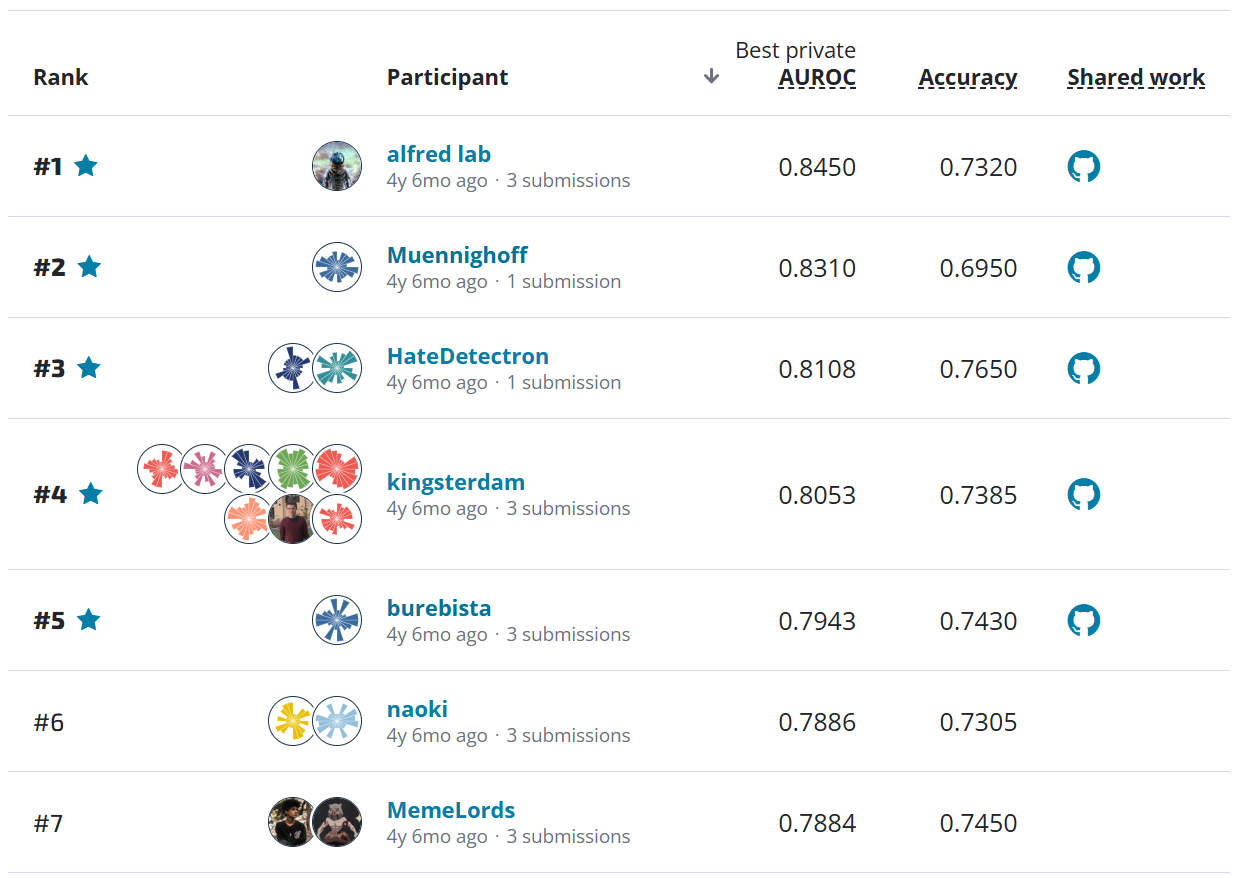
In the end, 8 teams qualified for final scoring and 6 achieved submissions that were validated as differentially private. Winning solutions needed to interact with the data strategically in order to get the most value from each query. A few techniques proved most effective (for more detail, see the next section for the solution descriptions in the teams' own words!):
- Probabilistic Graphical Models (PGM): Both N-CRiPT and Minutemen used PGM-based approaches. Each team tailored their approach and applied new techniques to deal with the increased sensitivity of the temporal data.
- Rescaling Public Data: DPSyn used noisy marginals on the private data to guide a synthesis process that relied on sampling and reshaping records from the public 2019 data. This was a very successful technique, performing similarly to the second place Minutemen, despite the fact that the distributions of the final scoring data (2016 and 2020) were radically different than the 2019 data DPSyn was using. This approach seems very promising and worth further research.
-
Weighting, Clipping, and Archetypes: 200 records per individual is a large number of records. We saw three approaches to reducing the sensitivity of queries on the data:
- Several teams weighted the trip records so that the set of all trip weights for a given taxi summed up to n (reducing trip query sensitivity a manageable n, rather than 200). That worked extremely well on this data. However, we have seen some evidence in prior sprints that it may not work equally well everywhere, and understanding the impact of weighting on heterogeneous populations is another area for future research.
- Similarly some teams used clipping to reduce the amount of data taken from each individual (for example, taking only a random 50 trips from each taxi), which also performed very well here. Knowing where and how subsampling can occur without negatively impacting the data is key.
- Finally two teams reframed their queries entirely to look at low-sensitivity counts of types taxis rather than high sensitivity counts of trips. These were newer techniques, very different from what was used in previous sprints, and had mixed success. They naturally competed very well on lower epsilons, and showed very good performance at maintaining the distribution of taxi types, but they struggled more with maintaining the distribution of trips in all community areas. These approaches will very likely benefit from further work.
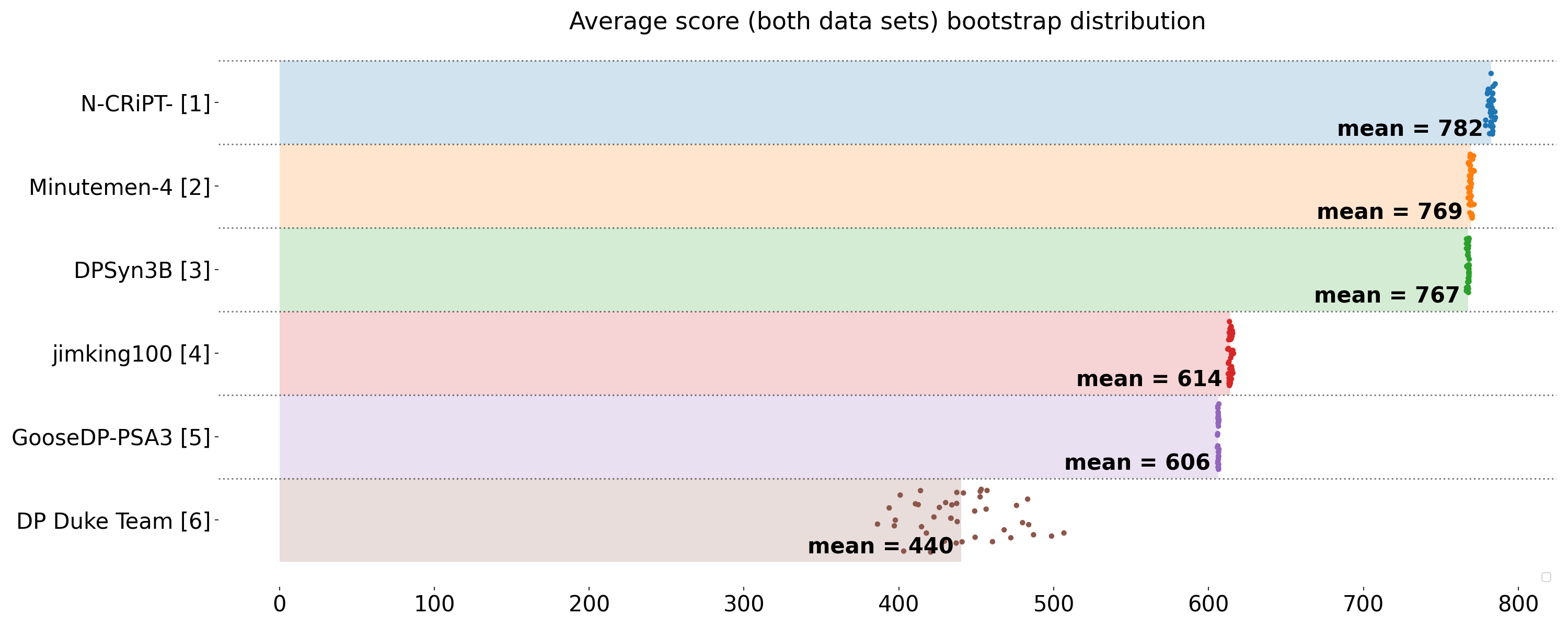
Visualization of final scoring runs showing the score distribution averaged across final scoring datasets (2016 and 2020) and epsilons (1 and 10), displayed for teams whose solutions were validated as differentially private.
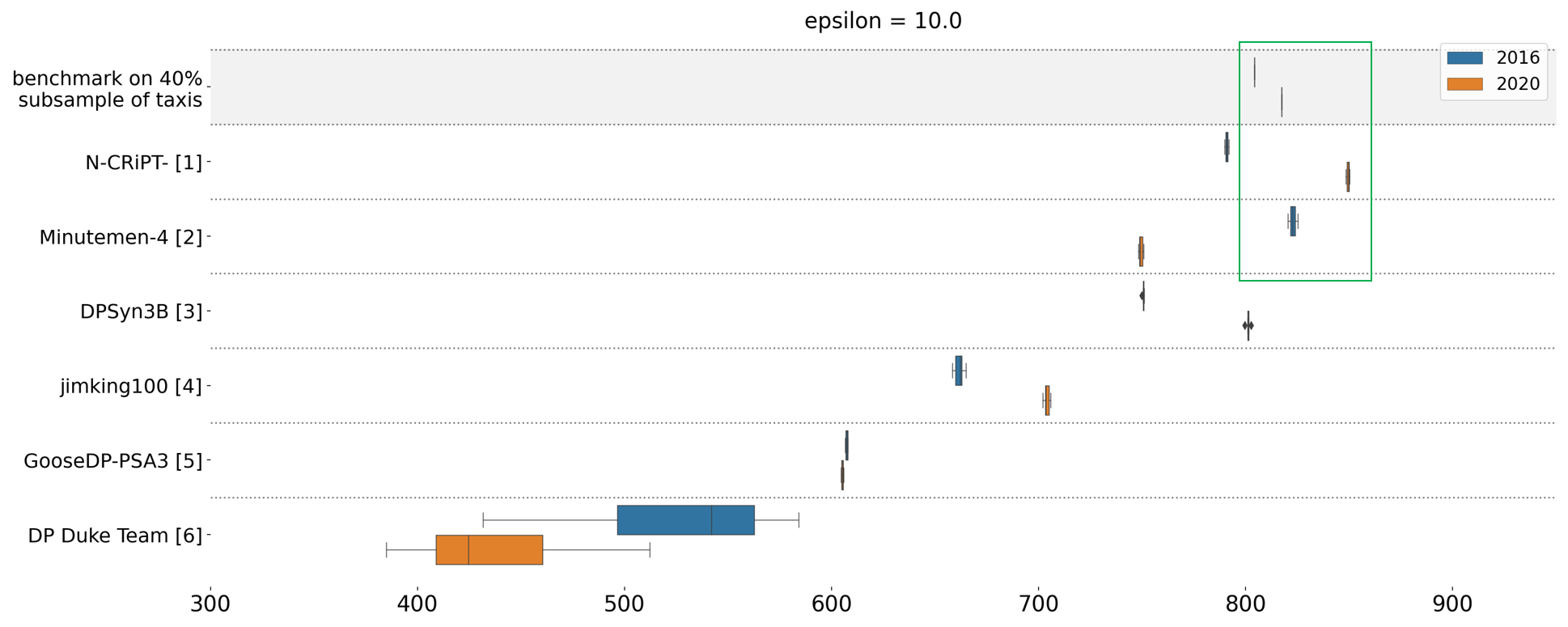
Final scoring distribution run on each data set (2016 and 2020) for epsilon 10. Each box represents the 25th, 50th (median), and 75th percentiles, while whiskers represent 1.5 times the interquartile range.
Benchmark at top shows a random subsample of 40% of taxis per data set, a data sharing approach that is not differentially private. The green box highlights winning solutions that outperformed this benchmark, demonstrating synthetic data approaches that are both more private and more accurate than subsampling.
When the NIST synthetic data challenges started in 2018, there was skepticism as to whether synthetic data was feasible with differential privacy. Over the course of the 6 sprints across two challenges, we have seen the competitors rise to the occasion, discover unexpected powerful tricks and techniques, and address problems such as large, complex feature spaces, sparse data, high sensitivity queries (temporal data), heterogeneous map segments, small epsilon values, edit constraints and all the complexities of real world data.
They were able not only to perform well on these real world problems; the top performers were also able to demonstrate better performance on both privacy and accuracy than traditional privacy techniques.
Random subsampling of records is a commonly used technique for releasing microdata while protecting privacy, for instance as used for the widely referenced American Community Survey. However, subsampling still involves releasing records of real individuals who may be vulnerable to reidentification, especially in data with many features. It also involves discarding large portions of the data (60% in this case), which can introduce disparately large error into the distributions of complex, diverse communities like those that are emphasized in this challenge.
In contrast, synthetic data generators train their models on the complete input data distribution, using everyone's records. This gives them the potential to outperform subsampling and other exclusion-based techniques, and that is indeed what we see in this sprint. The top teams were able to exceed the accuracy scores of the 40% subsampling benchmark, one on each data set, while providing formal privacy guarantees through differential privacy.
Congratulations to all the participants in this sprint! Meet the winners below and check out their approaches to help public safety agencies share data while protecting privacy!
Open Source Development Contest¶
One of the key goals of the Differential Privacy Temporal Map Challenge is to advance de-identification technologies that are useful and responsive to the public safety community.
To that end, there is a final phase to the challenge this summer where qualifying teams have the opportunity to advance the quality, generalizability, and openness of their solutions. Following the final algorithm Sprint, teams that submitted to final scoring in any sprint and whose algorithms that have been validated as differentially private are invited to make their source code open source with an appropriate license. Qualifying teams are also invited to submit a Development Plan describing how they would improve their code and documentation. See this forum post for further information.
Meet the winners: Sprint 3¶
N - CRiPT¶
Place: 1st
Prize: $25,000
Team members: Bolin Ding, Xiaokui Xiao, Kuntai Cai, Ergute Bao, Jianxin Wei
Hometown: China
Affiliation: National University of Singapore; Alibaba Group
Background:
We are a group of researchers interested in differential privacy.
What motivated you to participate?:
To apply our research on differential privacy in a practical setting.
Summary of approach:
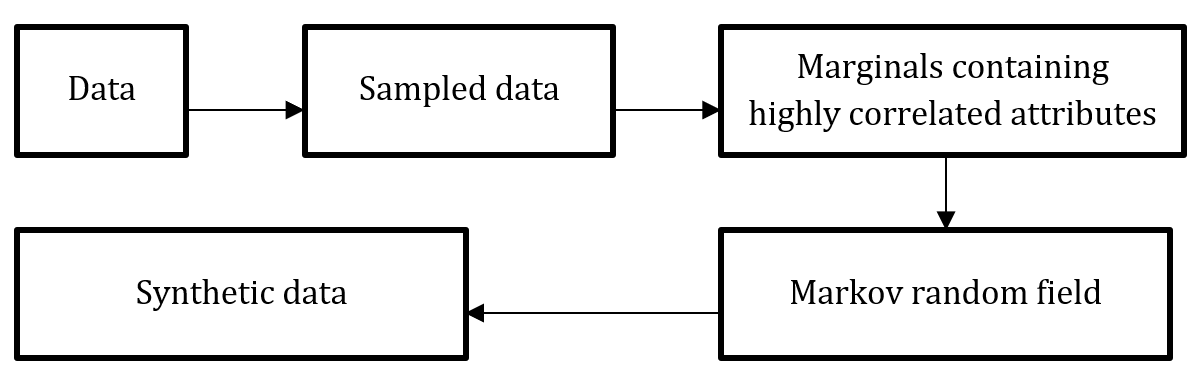
We used the public dataset to select a set of marginals that contain highly correlated attributes. We sample a collection of trips for each taxi to lower the sensitivity of marginals. Then, we inject noise to those marginal to achieve differential privacy, and used those marginals to construct a Markov random field (MRF). Finally, we use the MRF to generate synthetic data.
Minutemen¶

|

|

|

|

|

|
Place: 2nd
Prize: $20,000
Team members: Ryan McKenna, Joie Wu, Arisa Tajima, Brett Mullins, Siddhant Pradhan, Cecilia Ferrando
Hometown: Cumberland, ME; Norristown, PA; Tokyo, Japan; Gainesville, GA; Mumbai, India; Torino, Italy
Affiliation: UMass Amherst
Background:
We are graduate students at UMass who do research on differential privacy.
What motivated you to participate?:
We are all differential privacy researchers and we found the temporal and geographical aspect of the challenge very interesting.
Summary of approach:
We developed an adaptive-grid style mechanism to effectively deal with the imbalanced data. We begin by invoking the analytic Gaussian mechanism to measure all 1-way marginals. Then, we inspect the noisy histograms and determine which parts of the domain we can measure at a finer granularity. Then we invoke the analytic Gaussian mechanism again to measure cells in the noisy 2-way marginals that could have sufficiently large count (which we decide based on the noisy 1-way marginals). We repeat this for 3- and 4- way marginals. After measuring all of these statistics, we post-process the measurements using Private-PGM, which constructs a graphical model that preserves the measured information well, and we generate synthetic data from that model.

After measuring the 1-way marginals for column1 and column 2, we inspect the noisy counts and identify cells whose count is above a given threshold (in this case, 100). If the count for particular values in column 1 and column 2 are both above the threshold, then we will measure the number of records that have both of those values at the same time. In the figure above, the cells in the 2-way marginal that we measure are color-coded in green.
DPSyn¶
Place: 3rd
Prize: $15,000
Team members: Ninghui Li, Zitao Li, Tianhao Wang
Hometown: West Lafayette, IN; China
Affiliation: Purdue University
Background:
We are a research group from Purdue University working on differential privacy. Our research group has been conducting research on data privacy for about 15 years, with a focus on differential privacy for the most recent decade. Our group has developed state-of-the-art algorithms for several tasks under the constraint of satisfying Differential Privacy and Local Differential Privacy.
What motivated you to participate?:
We have expertise in differential privacy. We also participated in earlier competitions held by NIST and got very positive results. We believe this is a good opportunity to think more about real world problems and explore the designs of algorithms.
Summary of approach:
Our approach is to modify the public dataset provided in the development phase with the privatized marginals from the target dataset. We first reweight each record in the public dataset to limit the influence of each individual taxi_id. Then we split the privacy budget and query the target dataset to obtain the two-way marginal of pickup_community_area + dropoff_community_area, one way marginal of company_id, and one way marginal of payment_type when privacy budget is small or two way marginal of pickup_community_area + payment_type when the privacy budget is large. Then we replace the attributes of records in the public datasets to match the privatized marginals.

Jim King¶

|
Place: 4th
Prize: $10,000
Team members: Jim King
Hometown: Mill Valley, CA
Background:
I am a highly successful real estate agent who happens to like data science. My Computer Science degree, MBA in Finance and 20 years of experience in the tech field also help.
What motivated you to participate?:
I love learning, a challenge and competition! I was unaware of the differential privacy field prior to the contest so there was a steep learning curve with plenty of challenges. The competition and the chance to win cash was certainly a motivating factor. My fifth place showing in the 2nd Sprint provided additional motivation for the 3rd Sprint.
Summary of approach:
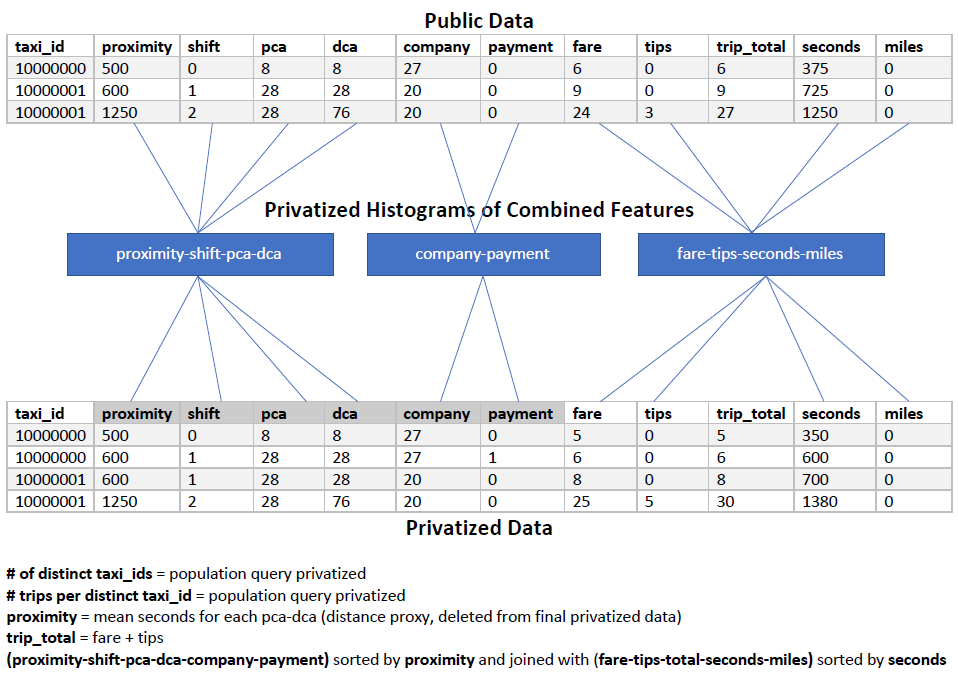
The main idea is to combine features in the pre-processing phase, create privatized histograms of the features, then during the post-processing phase create the simulated data. The individual taxis are created by simply counting the number of taxi_ids, adding noise and then iterating through the privatized count. The number of trips per taxi_id is calculated by counting the taxi_ids with k number of trips (k = 1-200) and adding noise to each bin.
A total of 5 queries are used:
1) Count of distinct taxi_ids 2) Count of distinct taxi_ids with k number of trips 3) Histogram of the proximity-shift-pca-dca feature by taxi_id 4) Histogram of the company-payment_type feature by taxi_id 5) Histogram of fare_codes feature by taxi_id
A dictionary is created containing a trip_seconds estimate for each pca-dca combination that is used in the post-processing process to algin the fare codes with the pca-dca combinations.
GooseDP¶

|

|

|

|
Place: 5th
Prize: $5,000
Team members: Christian Covington, Karl Knopf, Shubhankar Mohapatra, Shufan Zhang
Hometown: Pfafftown, North Carolina, USA; London, Ontario, Canada; Kolkata, India; Anhui, China
Affiliation: University of Waterloo
Background:
We are graduate students at the David Cheriton School of Computer Science at the University of Waterloo.
What motivated you to participate?:
We are interested in practical applications of privacy research and gaining experience in developing solutions to real-world problems.
Summary of approach:
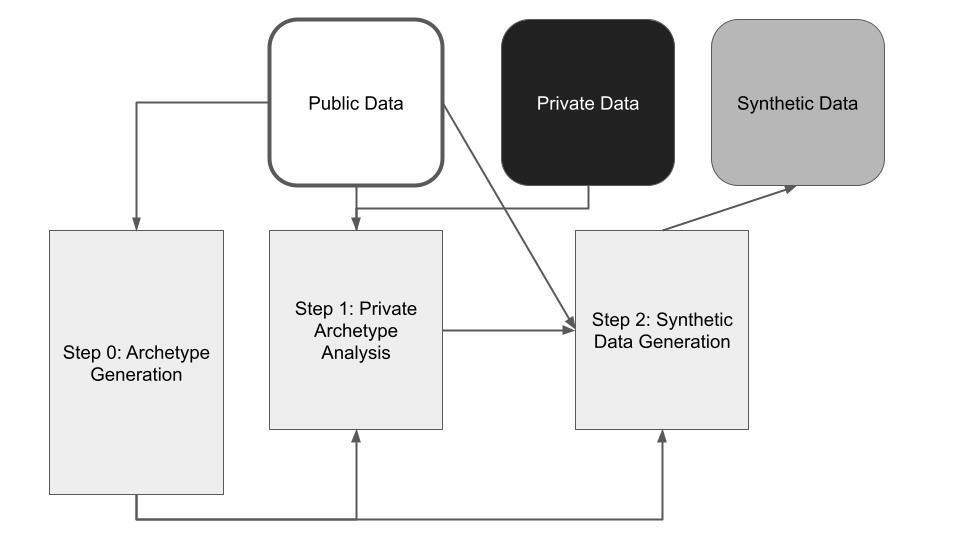
To create usable private data while guaranteeing data contributor privacy, we have designed a synthetic data generation pipeline which seeks to maintain key data characteristics while only making low-sensitivity queries to private records. To do this, we construct profiles of representative record distributions, which we call archetypes, from the public data. Using these archetypes, in addition to a small number of private queries, we can construct a set of partial synthetic records. With additional pre and post processing using the public data, as well as domain knowledge, we can create a complete synthetic data set with the missing attribute values.
Progressive Prizes¶
Finally, congratulations to Minutemen, DPSyn, N-CRiPT, and Jim King who also won a $1,000 progressive prize this sprint! As a reminder, progressive prizes are awarded part-way through each sprint to four eligible teams with the best scores to date, with precedence given to solutions that are pre-screened as satisfying differential privacy.
Thanks to all the participants and to our winners! Special thanks to NIST PSCR for enabling this fascinating challenge!
Chicago taxi image courtesy of flickr user Timothy Neesam.