Clog Loss: Advance Alzheimer's Research with Stall Catchers¶
A video representation of what the neural network "sees" by challenge winner ZFTurbo
We see a tremendous opportunity to incorporate these new models into Stall Catchers, where they could work in concert with human-based analysis to double or triple our analytic throughput without compromising data quality! This could get us closer to an Alzheimer’s treatment at unprecedented analytic speeds.
Pietro Michelucci, Project Lead, Stall Catchers
5.8 million Americans live with Alzheimer’s dementia, including 10% of all seniors 65 and older. Scientists at Cornell have discovered links between “stalls,” or clogged blood vessels in the brain, and Alzheimer’s. The ability to prevent or remove stalls may transform how Alzheimer’s disease is treated.
Stall Catchers is a citizen science project that crowdsources the identification of stalls using research data provided by Cornell University’s Department of Biomedical Engineering. Finding these stalls is extremely time intensive, especially as only around 1% of image stacks contain stalls. The researchers behind Stall Catchers believe that some portion of the data may be within reach of machine learning models. Model predictions would only be used in cases where models had been validated to meet the researchers’ data quality requirements.
In this challenge, participants were tasked with building machine learning models that could classify blood vessels in 3D image stacks as stalled or flowing. Even with this difficult data format, more than 900 participants answered the call and generated over 1,300 submissions!
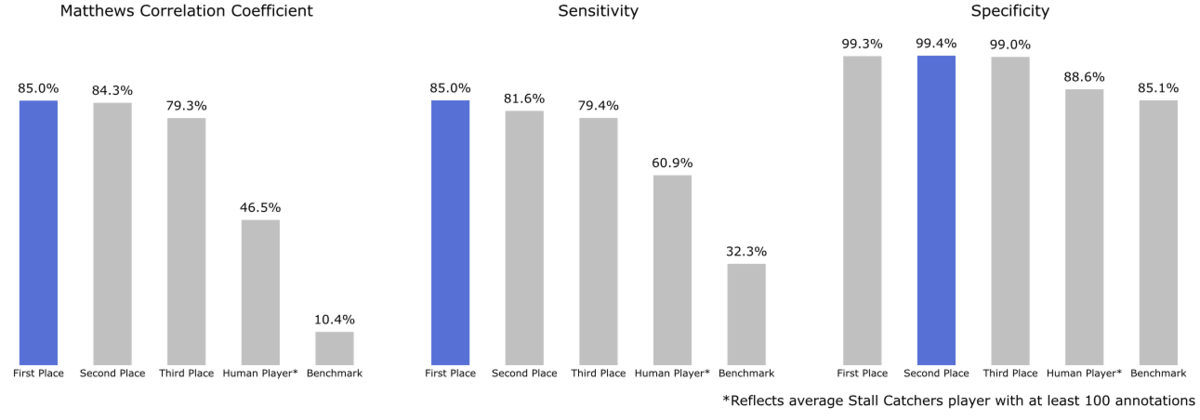
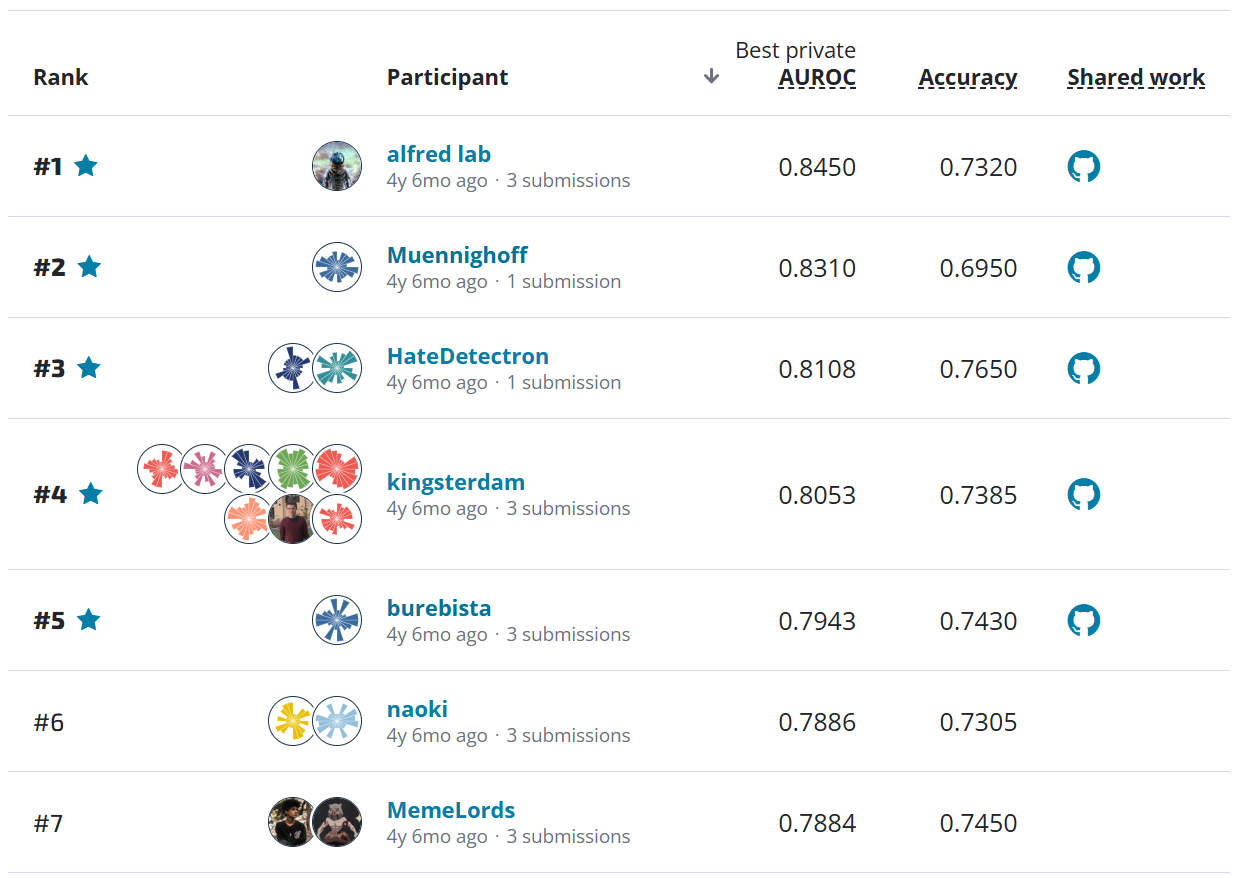
The top-performing model was able to achieve an impressive 0.855 Matthew's correlation coefficient (MCC) score, surpassing 85% sensitivity (true positive rate, i.e. classifying stalled vessels as such) and 99% specificity (true negative rate, i.e. classifying flowing vessels as such). This level of specificity means that models like this can be used to process large volumes of data while minimizing the risk of losing the stalled cases that are so important to research.
The greatest immediate promise from these results lies in combining machine and human predictions to accelerate research. Currently, specialized methods aggregate multiple players into a single "crowd answer" that achieves a 0.99 sensitivity and 0.95 specificity threshold on 95% of datasets. These results suggest a couple exciting avenues to carry forward the competition results: 1) use algorithms and humans in tandem to process data far more quickly, and 2) continue experimenting to develop methods that combine algorithms and humans in ways that exceed the performance that either demonstrates alone.
All the prize-winning solutions from this competition are linked below and made available for anyone to use and learn from. ** Meet the winners and learn how they built the best stall detectors to advance Alzheimer's research! **
Meet the winners¶
Roman Solovyev¶

Place: 1st
Prize: $5,000
Hometown: Moscow, Russia
Username: ZFTurbo
Background:
I’m Ph.D in microelectronics. Currently I’m working at the Institute of Designing Problems in Microelectronics (part of Russian Academy of Sciences) as a Leading Researcher. I often take part in machine learning competitions. I have extensive experience with GBM, Neural Nets and Deep Learning as well as with development of CAD programs in different programming languages (C/C++, Python, TCL/TK, PHP etc).
What motivated you to compete in this challenge?
I always wanted to try Conv3D neural net models and it was good competition to use them. For the competition, I prepared a set of independent modules for faster 3D neural net model development and training.
Summary of approach:
The solution that gives the best result is divided into the following steps:
Stage 1 [region of interest (ROI) extraction]: For each video, only the part that is marked with an orange border in the video is extracted. To increase the speed of training, this part was saved as a numpy array in a zipped pkl file. Using a zip file significantly reduced the disk space requirements.
Stage 2 [Preparation of 5KFold cross-validation]: In my solution, I did not use all available videos (1.4 TB). I downloaded the micro dataset, and also downloaded all the available videos from stalled == 1 and additionally a large number of videos with stalled == 0 label. In total, I had 51,490 videos, where 49,603 had stalled == 0 and 1,887 videos had stalled == 1. I split them uniformly into 5 folds using the standard KFold function from the sklearn module.
Stage 3 [training of DenseNet121 3D]: This is the longest and most time-consuming stage of calculations. As the main neural network, I used a neural network built on the principles of the DenseNet121 network, which is used to classify images, but in a 3D version. I also converted the ImageNet weights into a 3D version, so that I would not start from scratch.
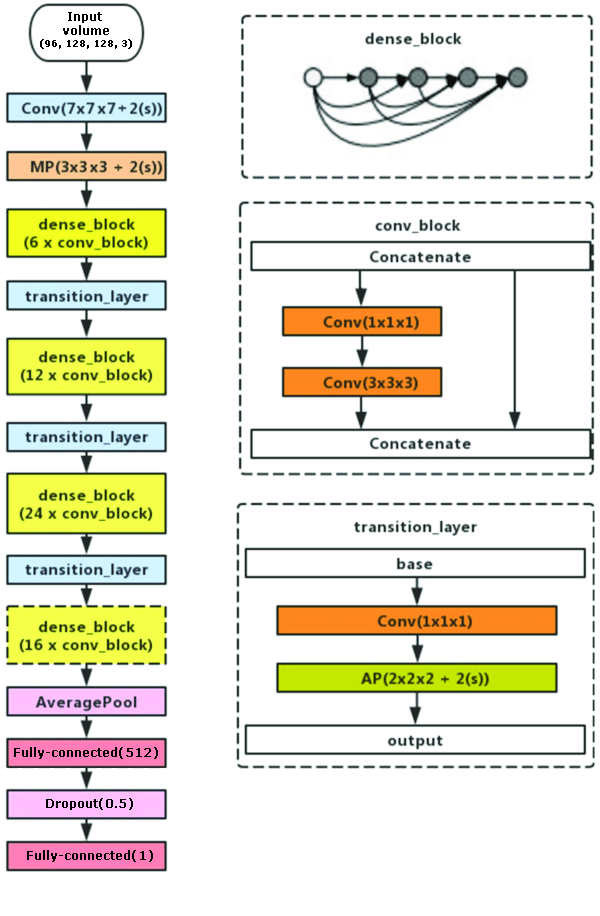
Structure of DenseNet121 3D
Stage 4 [inference for test set]: At the last stage, five models received after training (by the number of folds) were reduced by BatchNorm Fusion operation (using KITO) and combined into one model with a common input. Each test video is then run using this combined model. The test time augmentation (TTA) approach is used, where all 8 possible video reflections on all axes are fed into neural network and then the prediction is averaged. The MCC metric was used on LB, and in the problem it was required to predict not probabilities, but binary stalled label. The selection of the optimal THR value was carried out using LeaderBoard. In my case the optimal value for threshold was about 0.7.
Check out ZFTurbo’s full write-up and solution in the competition repo.
Kirill Brodt¶

Place: 2nd
Prize: $2,000
Hometown: Almaty, Kazakhstan
Username: kbrodt
Background:
Currently I'm doing research at the University of Montréal in Computer Graphics, using Machine Learning for problem solving such as posing 3D characters via gesture drawings. I got my Masters in Mathematics at the Novosibirsk State University in Russia. Lately, I've fallen in love with machine learning, so I enrolled in Yandex School of Data Analysis and Computer Science Center. This led me to develop and teach the first open Deep Learning course in Russian. Machine Learning is my passion and I often take part in these competitions.
What motivated you to compete in this challenge?
I like competitions and to solve new problems, at least new to me. I’ve never worked with 3D images so in this challenge I learned new things, like how to store, read and process such data efficiently.
Summary of approach:
The best models for 2D image recognition are 2D convolutional neural networks (CNNs). Most likely this will be true for 3D. So the 3D CNNs were chosen, namely ResNets. Thanks to the provided regions of interest on videos one can crop it to reduce significantly disk and, hence, RAM usage.
To deal with different spatial resolutions of frames they were resized to 160x160. Depth dimension was zero-padded until the longest depth of all samples in the batch. As the dataset is highly imbalanced, a balanced sampler with 1/4 ratio of positive (stalled) classes was applied. This also makes training faster.
The heavy ResNet101 model was trained with binary cross entropy loss with standard spatial augmentations like horizontal and vertical flips, distortions and noise. Finally, deep learning is data-hungry, so the model was trained on the full tier 1 dataset and all stalled samples with crowd score> 0.6 from tier 2 dataset. The predictions of five different snapshots on various epochs of the same model were averaged.
Check out kbrodt’s full write-up and solution in the competition repo.
Laura Onac¶

Place: 3rd
Prize: $1,000
Hometown: Ocna Mures, Romania
Username: LauraOnac
Background:
I am a graduate student about to complete my master’s program in Applied Computational Intelligence, and I’ve been working as a Machine Learning Engineer for the past two years. I am experienced in solving natural language processing and computer vision tasks using machine learning.
What motivated you to compete in this challenge?
I was looking for a meaningful project idea for my dissertation thesis when I stumbled upon this competition. The problem seemed challenging and I knew the work could contribute to a great cause, so I decided to compete and write my thesis around it.
Summary of approach:
Data selection: Due to hardware limitations and also the high class imbalance in the full training data set, I only worked with a selected portion of the data. The strategy consisted in selecting only data from tier 1 based on the project id, with the intuition that this might help model the diversity present in the large data set. The final experiments were conducted using the micro subset merged with subsets of at most 500 samples from each project, depending on availability. The final train set consisted of 7,931 videos, all from tier 1, with 91.1% of them being flowing.
Data preprocessing and augmentation: In terms of preprocessing, the areas outlined in orange from each video are cropped and then resized to 112 x 112 pixels. All three color channel of the videos are used, but before feeding the data into the neural networks, there are the usual feature scaling and standardization steps. Throughout the training phase, two types of data augmentations (rotations and flips) are performed on an entire video with a 25% chance each.
Models: The final experiments were conducted with three different spatio-temporal neural network architectures based on ResNet-18: R3D, MC3, and R(2+1)D. They were designed for video classification and pretrained for action recognition on the Kinetics-400 data set. The decision layer of each network was replaced with a single-neuron layer with sigmoid activation. The models were trained using the Adam optimizer, with a batch size of 1 video, and the binary cross-entropy loss, with class weights of 1 for flowing samples and 10.23 for stalled ones, to compensate for the class imbalance. The initial learning rate is set to 10^(-4), and was decreased over time using cosine annealing. Due to hardware limitations, the models were only trained for 30 epochs.
Results: A decision threshold higher than 0.5 was selected empirically and used for each model. The best result obtained using a single model was the one of the R(2+1)D model. But, the highest performance was achieved using an ensemble of two R(2+1)D models and an MC3 model. For the ensemble, a sample was considered to be stalled if at least two of the three constituent models had a decision level higher than their corresponding thresholds.
Check out LauraOnac’s full write-up and solution in the competition repo.
Azin Al Kajbaf and Kaveh Faraji¶

|

|
Place: MATLAB Bonus Award Winner
Prize: $2,000
Username: AZK90 and kaveh9877 (team AZ_KA)
MathWorks, makers of MATLAB and Simulink software, sponsored this challenge and the bonus award for the top MATLAB user. They also supported participants by providing complimentary software licenses and learning resources. Congrats to team AZ_KA as the top finalist using MATLAB!
Background:
My name is Azin Al Kajbaf. I am a PhD student at the University of Maryland. My area of focus is Disaster Resilience which is a part of the Civil Engineering department. My work involves employing probabilistic methods and machine learning approaches for assessment of natural hazards. For example, I use different machine learning methods such as Artificial Neural Networks for prediction of storm surge and down-scaling of future climate projections for precipitation frequency analysis.
My name is Kaveh Faraji. I am a PhD student at the University of Maryland and I work in the area of Disaster Resilience. My main research is focused on risk assessment of hazards such as flood and storm surge. I am also working on employing geospatial analysis and machine learning approaches in my research.
What motivated you to compete in this challenge?
Due to our research, we became acquainted with machine learning methods such as Artificial Neural Networks and Gaussian Process Regression, etc. We were interested to learn more about these methods so as a next step we started to study deep learning recently. We thought this skill might be useful in our research, too. We decided to participate in deep learning challenges because we believed that it can help us to learn these methods more effectively.
Summary of approach:
At first, we tried approaches that are mostly used in human action recognition. However, after a while we tried an approach that in our opinion was simple, faster and more suitable to the nature of the videos for recognizing stalled and flowing vessels. The approach that gave us the highest score was converting the videos to a combination of images and using transfer learning. The steps of the approach are as follows:
- Select a suitable set of input data from the training set which we thought might give us good results.
- Split videos to 4 equal groups of frames.
- Obtain the average of the pixels of frames in each group and used that as the representative of these frame in our training approach.
- Construct a single image that consisted of the mean of these groups of frames.
- Use a deep neural network (with retraining ResNet18) to classify testing videos as stalled or flowing.
Check out team AZ_KA’s full write-up and solution in the competition repo.
Thanks to all the participants and to our winners! Special thanks to MathWorks for enabling this fascinating challenge and to the Human Computational Institute and their Stall Catchers community for providing the data to make it possible!