We recently got a chance to pick the brain of Quoc Le, our Box-Plots for Education 1st place finisher. He answered some of our questions about himself, the competition, and data science in general.
Congratulations on winning the Box-Plots For Education competition! Who are you and what do you do?¶
I'm Quoc Le and I am a Sr. Data Scientist at Salesforce in San Francisco.
What first got you interested in data science?¶
I majored in Mathematics as an undergrad at Vanderbilt, and back in college I always thought I would do quantitative work for a living. I made the practical choice to work in software development and technology instead, but I was inspired when data science emerged as an actual career option in the past few years. So I went back and got a Masters in Predictive Analytics at Northwestern University, and now I am doing what I love (predictive modeling) while also leveraging my engineering background when dealing with big data and when scaling up machine learning.
How long have you been at Salesforce, what kind of problems do you work on, and what were you doing before?¶
I've been with Salesforce for almost 3 years, by way of the ExactTarget acquisition. These days I focus on Data Science projects aimed at uncovering analytical insights about Salesforce product usage. I've also helped with Natural Language Processing projects, for example trying to improve algorithms for sentiment analysis of business tweets.
Before becoming a Data Scientist at Salesforce, I was more focused on the engineering side, in particular on applications dealing with large social datasets from Twitter and Facebook.
What brought you to DrivenData or this problem in particular?¶
DrivenData's mission to do social good through data science really resonated with me, and giving back is something that Salesforce values as well through its integrated philanthropy model. I also spent time working at an educational company called Scientific Learning, so helping public schools more efficiently use their resources held a particular interest for me.
You ended up using some cool techniques like the hashing trick and tools like Vowpal Wabbit. How long have you been working on NLP problems, and how did you choose your tools for this particular problem?¶
I happened to work on NLP problems both during my masters and at Salesforce (doing social sentiment analysis). I learned through both of these experiences that computationally efficient approaches like online learning often work well for text classification problems, which typically involve highly-dimensional feature sets. Online learning that uses hashing trick, for example, is really efficient for representing sparse tf-idf matrices in a format that has a smaller memory footprint. Stochastic gradient descent as a technique for out-of-core learning also cuts down tremendously on training time without sacrificing too much accuracy in these types of problems. It's possible to use more sophisticated, computationally-intensive approaches for text classification, but online learning provided the fast feedback loop I was looking for, so I could focus more on feature engineering.
The two tools for online learning that I am most familiar with are Vowpal Wabbit and tinrtgu's online learner (there are obviously many more options). Vowpal Wabbit has a lot more functionality out of the box (like generating n-grams for you and supporting multiple passes), but tinrtgu's online learner handles the simultaneous fitting of multiple targets better so I went with that as we had 104 target variables in this competition. I also generally like Python for processing of textual data, and even if I did use Vowpal Wabbit I would prepare all the features in Python first.
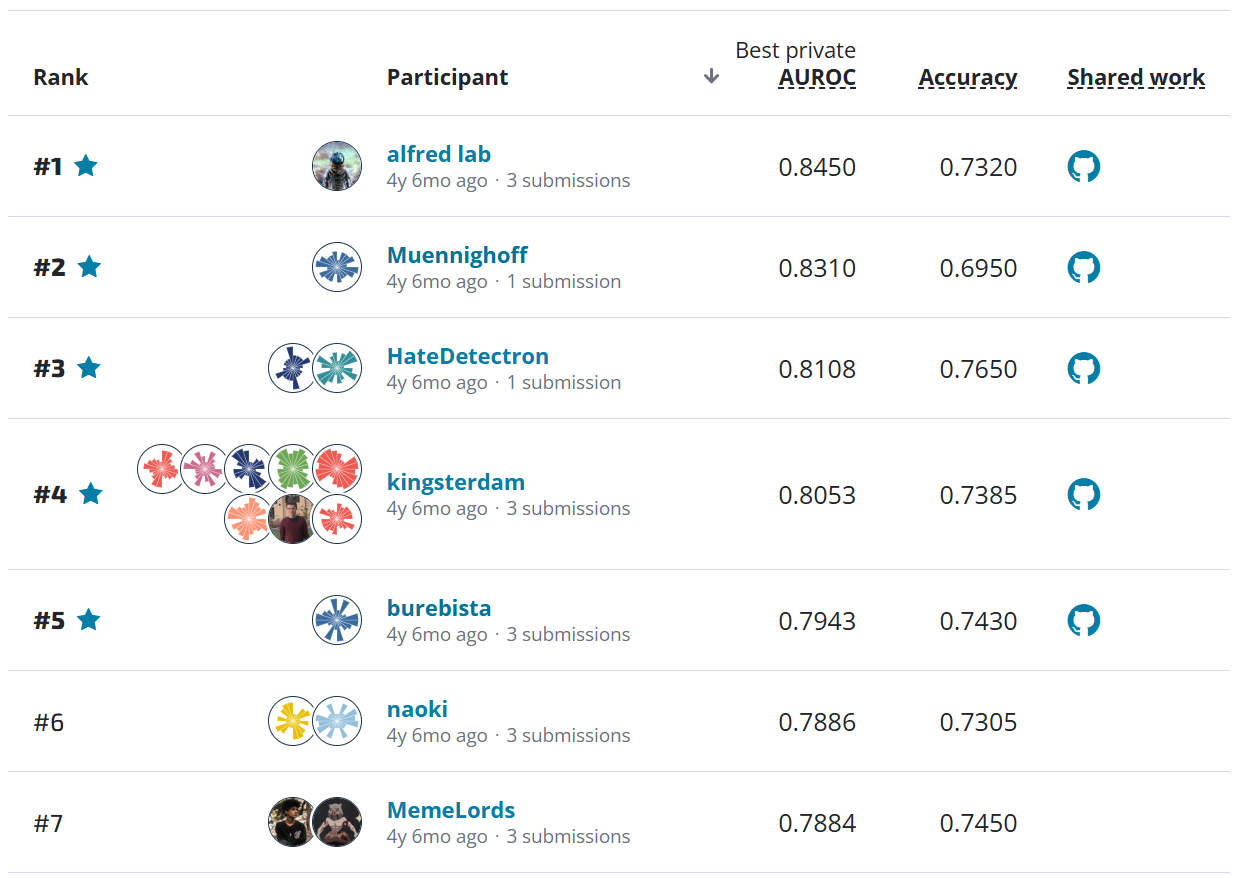
In addition to winning the competition, you also had the most submissions of any user. Do you think this was a significant benefit, or was it enough to rely on tools like cross validation?¶
I did create a lot of submissions (96 :), but I would also note that by submission #55 I already had a score good enough to win first place. Creating 55 submissions would have been about in the 70th percentile for top ten finishers, so not that far from the middle.
Here is a table I included in the model documentation that also provides a sense for what went into my submissions:
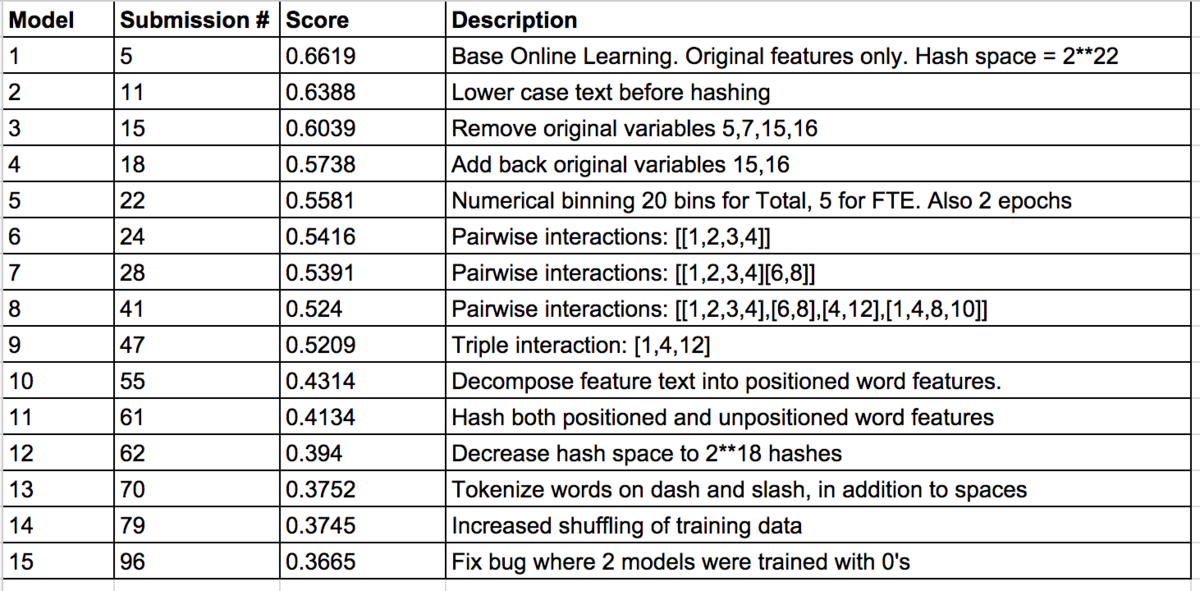
Cross-validation had limited usefulness for me in this particular competition, due to the differences between the training and test datasets. Given these differences, it made sense that Submission #55 had such a big positive effect, because it created features that allowed the algorithm to generalize better (i.e. do a better job of classifying targets when textual feature values were coded slightly differently between the training and test datasets).
Python was a major part of your process and code submission. What place does R have in your workflow if any, and what other languages do you like to use? What are your thoughts on the current and future scientific computing ecosystem?¶
I am fairly language agnostic, and my approach is to use the best tool for the job. I do admit to liking Python a little more than the rest, and Python is the tool I prefer for data munging, feature engineering, and general programming tasks (mostly using iPython notebooks). If I can stay in Python for doing EDA/Visualization (pandas/matplotlib) and modeling (sklearn) then that is ideal. However, there are many cases where I feel compelled to switch over to R, which I favor for more demanding visualization (ggplot) or more classical statistical analysis. Just really depends on what I am doing.
In Data Science (and Engineering), I think there's lots of room for different tools in the computing ecosystem. There are always tradeoffs and many tools that can capably do a given job.
What machine learning research interests you right now? Have you read any good papers lately?¶
I like to follow machine learning advances in text classification, and one recent paper that really blew my mind was "Text Understanding from Scratch" by Zhang and LeCun. In this paper, the authors perform text classification by training ConvNets not on words or phrases but on quantized characters, and the results looked really promising.
It seems like data science in particular has an incredible number of self-directed learners and people with nontraditional career paths. Do you have any recommendations for people trying to break into the field and learn the sort of applied skills you used in this competition?¶
Given the cross-disciplinary nature of data science, I think almost everyone comes from a "nontraditional" career path, as there really is no status-quo in my opinion. Being effective as a data scientist requires a broad range of skills, and I think the folks who are most successful are creative, independent learners who are ruthless about finding and addressing gaps in their skill sets. Data Science competitions like this one are a great way to understand one's potential weaknesses and discover areas that need work.
I would also add that making the transition into data science is a long journey, so get a good support group. There are lots of ways to do this, but I chose to do it via a formal masters degree. I could not have made the transition myself without the support and encouragement of my classmates and professors at Northwestern's Masters in Predictive Analytics Program.
Now some just for fun questions about your setup (hat tip to The Setup!) — in your daily personal and working life, what hardware do you use?¶
For my personal setup, I use a Macbook Pro laptop with 4 cores and 8 GB of memory. I supplement this with a Linux workstation with 8 cores and 32GB of memory.
And what software?¶
Python and R are my workhorses. I am happiest working in an IPython notebook or in RStudio. I do a bit of work in Hadoop and Hive, and on occasion I also need to work in Java/Eclipse for production systems.
A big thanks goes out to Quoc from the DrivenData team for taking the time to chat. Feel free to discuss this interview in the DrivenData community forum, and stay tuned for big news in the next few days! ;)