by
Michael Schlauch
We are very interested in how AI-based research assistants can help NASA, and we received a diverse variety of cutting-edge AI approaches from around the globe in the Research Rovers challenge. We are inspired by the prototypes the teams made and look forward to using AI-based research assistants to multiply NASA’s work in safe, secure, responsive and powerful ways.
Edward L. McLarney, Digital Transformation Lead for Artificial Intelligence and Machine Learning, NASA
Background¶
Information overload is real. With the vastness of the internet at our fingertips, the problem these days is often not accessing the information, but distilling it.
One particular realm in which this problem arises is for researchers attempting to understand a body of scientific literature, perhaps in a field that is relatively new to them. There may be hundreds of research papers that need to be read, or at least skimmed. The results of those papers, their sometimes subtle methodological differences, the varying reporting standards of individual authors and publications -- all need to be synthesized in order for the researcher to have a cohesive view of the field itself and their role in it.
It can be an arduous task, and it is a real skill to master the art of literature review, one that researchers hone throughout their careers. They'll continue to do so. But at the same time, new tools are emerging that build on advances in generative AI and promise to alleviate some of that burden for researchers, making this process potentially faster, more comprehensive, and more effective.
NASA partnered with DrivenData to explore the possibilities of these new tools by launching the Research Rovers: AI Research Assistants for NASA challenge from August-October 2023.
The Research Rovers challenge was developed with direct input from NASA researchers, in fields ranging from aircraft acoustics to complex systems, who described for the challenge design team the difficulties they faced in their current research workflows. We eventually narrowed in on a set of related tasks that researchers described as major pain points in this type of work, including summarization of existing research, identifying relevant papers, extracting the right keywords or search terminology, finding the leading experts in a field, and more. These tasks ultimately became the research assistant tasks which participants were asked to address with their submissions.
Results¶
For their final submission, participants provided a 5-10 minute video demonstration and short writeup describing their solution and its potential for assisting NASA researchers in their work. Making a submission was a fairly significant undertaking, as it typically involved prototyping an application with back-end and front-end capabilities that could be used by a hypothetical researcher -- and we are grateful to everyone who participated!
By the end of the challenge, 28 teams had made final submissions, which were then scored by a 10-person judging panel composed of researchers and digital transformation leaders at NASA.
Challenge organizers were genuinely impressed with the quality of the submissions, particularly given the 2-month timeframe within which participants had to develop a working prototype.
Here are a few common themes we saw across submissions:
LLMs¶
Many participants took advantage of recent developments in large language models like GPT-3.5/4 to tackle critical tasks like paper summarization and keyword extraction. LLMs were also the key component in chatbot features of several submissions, allowing users to ask questions about a specific paper of interest. Virtually all successful submissions incorporated some degree of prompt engineering. Judges also tended to favor approaches that allowed users to upload or select relevant research papers for LLM-driven analysis.
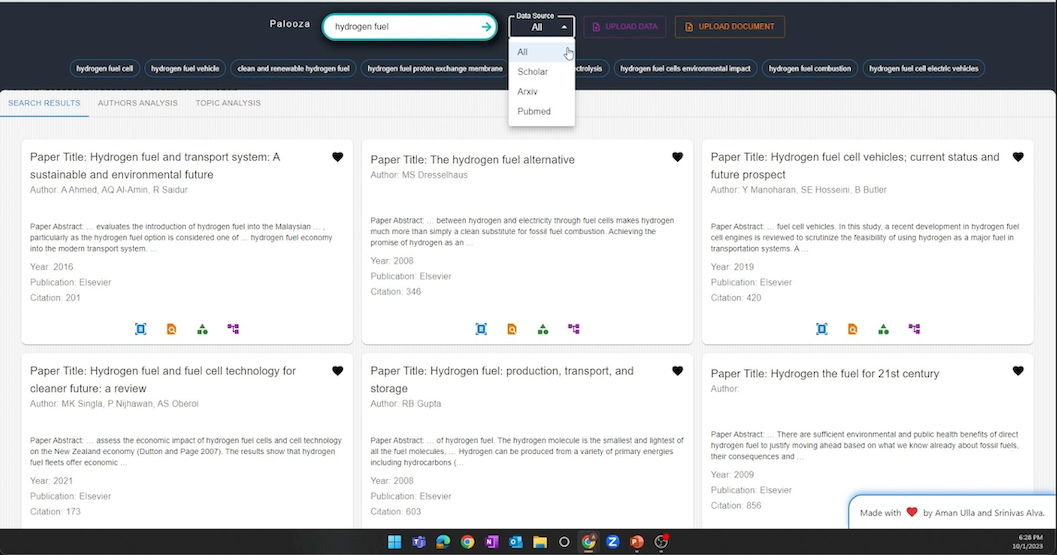
Paper recommendations from Google Scholar, arXiv and PubMed in the 1st place winners solution (NASAPalooza).
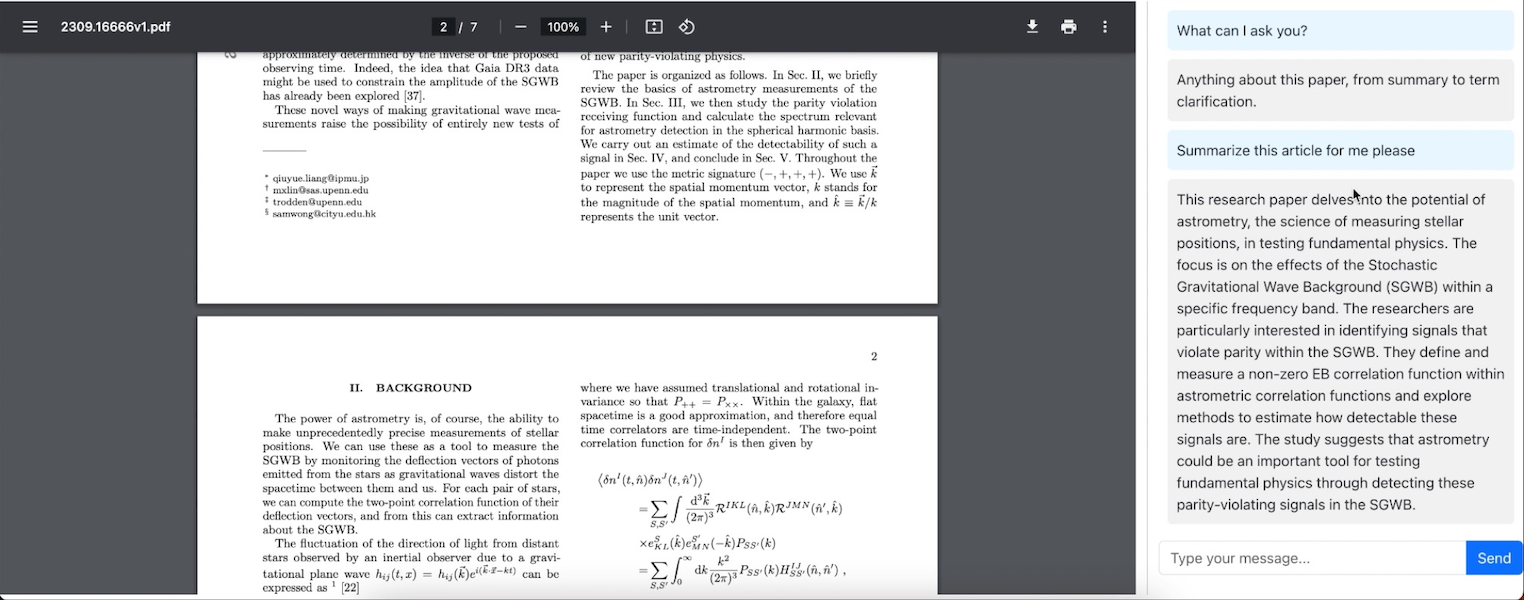
Chatbot Q&A sessions for a given research paper were a common feature in the top solutions.
A standard feature set¶
A core set of standard research assistant features were included in many submissions, showing that a platform based around these features is very achievable. A research assistant product that incorporates multiple features in a single platform would likely be appealing to NASA researchers. Some of these standard features included:
- Recommending relevant papers
- Extracting keywords and search terminology
- Summarizing papers
- Identifying leading experts and authors in a field
- Uploading a paper and exploring it with a chatbot
- Topic and trend analysis
The table below summarizes which features were included in each of the winning submissions, along with the models and data sources they used.
| Team / participant | Features | Models | Data sources |
| NASAPalooza | Paper search, paper recommendation, doc upload, paper summarization, chatbot, people search, keyword extraction, topic trends, dataset analysis | GPT-3.5 or GPT-4 | arxiv, Google Scholar, PubMed |
| IABlueTeam | Paper recommendation, paper summarization, keyword extraction, people search, chatbot | GPT-3.5 or GPT-4 | arXiv, OpenAlex, CrossRef, NTRS |
| lgarma | Topic clustering and visualization, paper recommendation, saved research collections, keyword extraction | GPT-3.5 bge-small-en-v1.5 |
arXiv |
| codeontherocks | Paper recommendation, keyword extraction, question recommendation | PaLM (Google) | OpenAlex |
Visualization¶
The winning solutions stood out for their visual appeal, presenting the breadth of information from a researcher's journey in an intelligible form. An honorable mention also goes out to George Moe for his innovative use of a "subway map" visualization to show the connections between different concepts in a research domain over time.
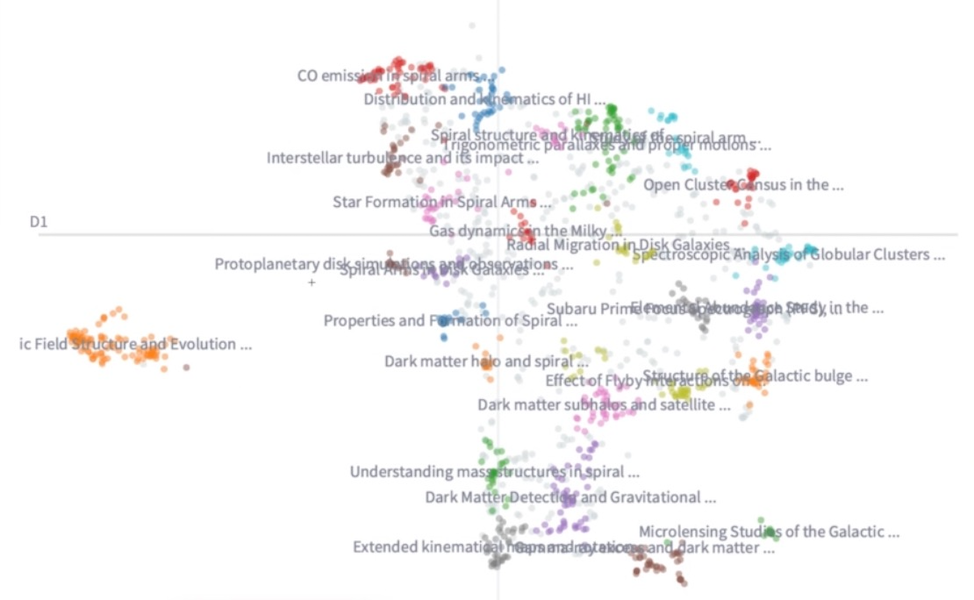 |
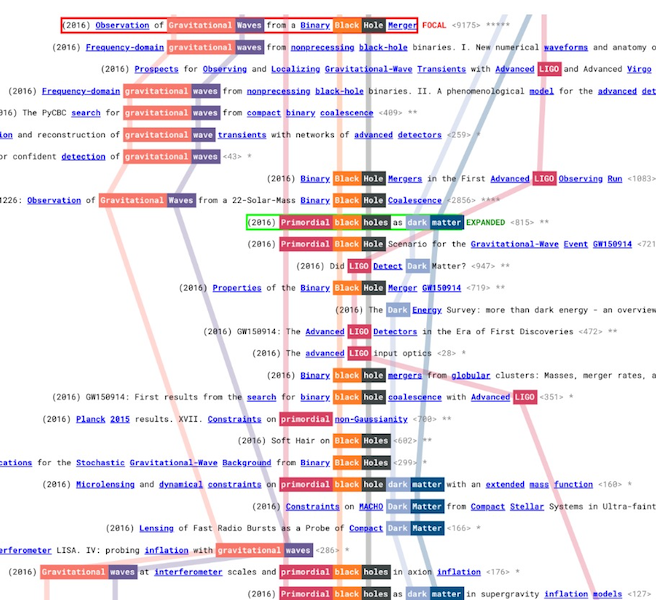 |
Topic visualizations in lgarma's 2nd place solution (left) and 'subway maps' from geosir's honorable mention solution (right).
Future opportunities¶
While there's significant promise in using AI for research assistant tools, many gaps still lie ahead in this space. Here are a few areas on which future work might be focused:
- Integrated and user-friendly research assistant platforms: One message that stood out clearly in our conversations with NASA researchers was the desire for a single platform that would provide a full research assistant toolkit, allowing them to discard the fragmented set of tools customized for particular tasks. Some of our winning solutions took a big, encouraging step in this direction. Making such platforms easy to use, visually appealing and even fun will be a big part of what separates the best offerings from the rest.
- Hallucination is a problem: No surprise here, but while LLMs turn out to be incredibly good at a variety of tasks in this domain, the potential for hallucination (when the models make false or misleading claims, despite sounding confident) is a largely unsolved problem. Future products relying on LLMs will need to not just summarize research papers and results, but also justify how they arrived at those conclusions, perhaps relying more heavily on retrieval-augmented generation.
- Compatability with multiple research archives: Although not explicitly an objective of this challenge, providing tools that allow researchers to seamlessly review research across different publishers and research archives would be a big improvement on the status quo. Currently, published research may be spread across a variety of different publishers, including free and open-source ones like those used in many of this challenge's demos (e.g. arXiv, OpenAlex, etc), commercial databases that require a subscription, as well as research indices like Google Scholar that may be comprehensive in scope but may sometimes not include entire papers (only titles and abstracts).
- Fairness: One question that has not yet received much attention is the extent to which research assistant tools, particularly those using LLMs, have the potential to amplify bias in our understanding of existing literature, for example by tending to surface papers that already have the most citations. The 3rd place solution in this challenge (Luis Garma) attempted to mitigate this bias by prompting the model to ignore author names when recommending papers.
Our hope is that this challenge has helped to advance our understanding of what is possible for AI-based research assistants and perhaps attract the attention of talented developers to the needs of researchers. We're extremely grateful to all the Research Rovers participants for supporting these efforts.
Meet the winners¶
Srinivas Alva and Aman Ulla (NASAPalooza)¶


Place: 1st
Prize: $13,000
Hometown: Bangalore, India and Ahmedabad, India
Background:
We are a duo known as the NASAPalooza team, both of us share a strong passion for exploring the depths of GenAI and creating solutions that tackle real-world challenges within the realm of AGI.
Srinivas Alva is a Data Scientist at ZS Associates, specializing in the transformation of high-grade research into commercial solutions. Currently, he is instrumental in designing and implementing GenAI solutions for both ZS clients and products. His skill set encompasses Synthetic Data Generation, Data Privacy, and Federated Learning Framework. Before joining ZS, Srinivas gained valuable experience in the IIoT industry, where he applied Vision-based models in portable devices like Nvidia Jetson Nano. He holds an M.S. degree in AI and ML specialization from Gujarat University, earned in 2019. His expertise and experience make him a valuable asset in the field of data science and Generative AI.
Aman Ulla is a passionate technology enthusiast deeply committed to fostering innovation. As an individual who relentlessly pursues excellence, his tech journey has been punctuated by impressive achievements. He has diligently refined his abilities in the development, deployment, and scaling of AI and ML models, offering substantial contributions to GenAI projects. Currently, he takes great pride in his role as a key figure at ZS, where he continues to push the boundaries of AI innovation. His educational background includes a Master's in AI and ML from John Moorse University, UK. He has demonstrated his powerful contribution by obtaining a patent in the field of AI.
What motivated you to compete in this challenge?
Our decision to participate in this challenge was driven by the recognition of an exciting opportunity. We saw the chance to utilize our expertise in GenAI to assist researchers in simplifying their work. Instead of manually running multiple queries, downloading numerous papers, and sifting through extensive metadata, we aimed to streamline NASA's research processes. We achieved this by creating a system that effectively comprehends and synthesizes research literature across different domains, that powered by GenAI. Importantly, our solution is designed to be easily deployable in various cloud environments with minimal or no adjustments required.
Summary of approach:
Our approach tackles the challenge researchers encounter when trying to keep up with scientific literature. This challenge involves sifting through numerous papers, each with distinct terminology and formats, resulting in time-consuming literature reviews and analysis. As the NASApalooza team, we've developed Palooza, a web application serving as the researcher's central hub. Palooza offers quick access to paper insights, summaries, and mind maps, simplifying the identification of research gaps and conclusions. Researchers can easily explore nested citations and engage in Q&A sessions on papers. This solution effectively addresses issues like information overload, lengthy review processes, interdisciplinary hurdles, relevance filtering, and efficiency gaps within research workflows.
Itay Inbar and Aviv Yovel (IABlueTeam)¶


Place: 2nd
Prize: $8,000
Hometown: Tel Aviv, Israel
Username: avivyovel & itayinbar
Background:
Aviv Yovel serves as the Chief Technical Officer (CTO) of Consiglieri, a startup advisory firm dedicated to supporting startups at all stages. Leveraging his LLM knowledge, Aviv aids startups, venture capitalists, and professionals in intricate endeavors such as investments and mergers & acquisitions (M&As). Prior to his role at Consiglieri, Aviv held positions as a Team Lead, Tech Lead, and Full Stack Developer at various companies and startups. He also boasts several years of experience with Natural Language Processing (NLP).
Itay Inbar is a software engineer and assistant researcher at i-BrainTech, a tech startup with a focus on neuroscience. Concurrently, he is a neuroscience student at Ben Gurion University and a research assistant in a computational neuroscience lab. Itay possesses experience in machine learning, deep learning, and full stack development. Additionally, he has dedicated five years as a volunteer in two youth movements, serving diverse age groups and communities across Israel.
What motivated you to compete in this challenge?
Ever since we were 14, we've shared a passion for building products and solving problems together. Over the years, we each forged our unique paths: Itay delved into neuroscience research, while Aviv became a CTO and tech lead for LLM-based startups. When we came across the NASA competition, we instantly recognized how it aligned with our values and the expertise each of us brings to the table. Our initial idea resonated strongly with researchers and acquaintances in academia. Their enthusiasm further motivated us to refine our concept and present it to NASA.
Summary of approach:
- We began with the ideation process. Given Itay's familiarity with the world of research, we collaborated to refine our initial concept. We then presented our idea to other researchers and acquaintances in academia, our target audience. After several iterations and discussions, we finalized the features. With a well-defined idea in hand, we enthusiastically moved on to planning the product.
- After finalizing the product specification, we began the development phase. We selected ReactJS for the client side due to its widespread popularity as a JavaScript library for building user interfaces. Our familiarity with it ensures ease of maintenance, even by those outside our team. On the server side, we opted for Python. This choice was influenced by Python's intuitive nature, ease of learning, and its comprehensive support for the platform's requirements, making it accessible for collaboration beyond our team.
- The caching mechanism was designed in response to frequently repeated pieces of data. Our primary objective was to minimize the number of requests made to OpenAI (ChatGPT). Additionally, we ensured that each service utilized the appropriate model from OpenAI's portfolio, considering both model type and size as well as token limits. This strategy aimed to achieve optimal results while minimizing costs associated with OpenAI usage.
- The engineering of the prompts was conducted by our team, drawing from our expertise in the LLM world and adhering to academic best practices. Each prompt underwent multiple testing sessions to ensure consistent and optimal results over time.
Luis Garma¶

Place: 3rd
Prize: $5,000
Hometown: Mexico City, Mexico
Username: lgarma
Background:
My name is Luis Garma. I recently obtained my PhD in astrophysics, where I studied the motion of stellar bars in spiral galaxies. Currently, I work as a data scientist in a local startup, where I research and develop solutions using Artificial Intelligence.
What motivated you to compete in this challenge?
The revolution we are witnessing in the world of artificial intelligence is incredibly fascinating. All the news and innovations are happening at breakneck speed, and I wanted to be part of it. In particular, this challenge hit close home due my personal experiences during my PhD.
I had some expirience working with vector databases and topic modeling, and recognized the oportunity. Moreover, the chance to work on a challenge that could help NASA researchers was a significant source of motivation.
Summary of approach:
My solution consists of a Streamlit web application that leverages the capabilities of Large Language Models (LLMs) to perform simple reasoning tasks. The app allows users to create “research collections”, which are a curated set of papers metadata obtained from ArXiv.
Although my solution uses OpenAI models, users never interact directly with them in a chat interface. Instead, I am harnessing the LLM capabilities to identify and extract relevant information for ArXiv titles and abstracts. This includes generating relevant keywords, identify underlying topics, and provide users with personalized paper recommendations.
Joe Muller¶

Place: 4th
Prize: $4,000
Hometown: Arlington, Virginia, USA
Username: codeontherocks
Background:
My name is Joe Muller and I am a full stack software developer. I primarily work on cross-platform mobile applications using the Flutter UI framework but I also have experience with JavaScript and Python. I live in Pentagon City with my wife and 2 cats.
What motivated you to compete in this challenge?
I have been actively engaged in the "AI Engineer" community since it sprang up in November 2022. I spend a lot of my free time playing with new AI developer tools and experimenting with new technologies. The rapid advancements of AI initially made me feel anxious about the future of software development (and society at large), but by using these tools in my daily routine, I've been able to calm my nerves a bit. Part of my reason for competing in this challenge was to demonstrate to myself the utility of AI.
On a more practical note, I believe that generative AI is particularly well suited for tasks that require equal parts structure and creativity. It is incredible at augmenting the human thought process by introducing new ideas, finding unique connections between concepts, and replying to your questions with "thoughtful" answers. I have been using ChatGPT as a sort of AI cofounder for several months now; mapping out new projects, planning marketing campaigns, exploring new features. When I saw the aim of this competition was to create an AI research assistant, it aligned strongly with my own impression of what these tools are useful for.
Summary of approach:
My goal was to infuse OpenAlex with the creative powers of modern AI. More specifically, I wanted to use AI to figure out how a researcher should traverse new research terrain. Many times, the key to quickly becoming familiar with a new field or domain is simply knowing what questions to ask and what terms are important.
In this metaphor, OpenAlex is the terrain, containing a vast amount of highly-connected and semantically labeled research content. Generative AI tools then, are the dynamically updated map that guides you through the terrain based on your desired direction.
My approach was to realize this relationship in an easy to use mobile application. At its core, Astrolex operates on a simple loop: search, select, expand, repeat. The user can search for a topic or term in OpenAlex and then repeatedly use a generative AI tool to figure out what the best next step would be.
George Moe¶

Place: Honorable Mention
Hometown: Chicago, Illinois, USA
Username: geosir
Background:
George is the CTO and a co-founder of Fliteworks, a venture-backed startup helping utility-scale solar farms monitor their vast properties and electrical systems using automated drones. He graduated from Harvard in 2021 with a BA in Computer Science and a minor in Philosophy.
What motivated you to compete in this challenge?
I've long believed the most profound use of AI will be to expand our understanding of the universe. A system that can reason directly on the content of research could pierce the intractable mass of knowledge to discover long-range connections that inspire new physics, new materials, new approaches, new science. In my senior thesis, I aimed in that direction by developing a way to structure scientific progress as threads of ideas which can be navigated like a map—first by researchers, then one day automatically, by their AI assistants. When I heard about this challenge, I knew it was the right place to propose this idea to the broader AI effort.
Summary of approach:
As papers are published at a greater rate than ever, it has become difficult to dive into an unfamiliar topic and gain an intuitive grasp of the research landscape: the timeline of ideas, the key authors, the relevant articles both well-known and niche. Part of this is because our current tools for paper discovery focus on fine-grained search; they excel at returning narrow results when the keywords are known. However, that starting point is often unknown—a higher perspective is required.
What if the research landscape could instead be navigated like a map? Where the course of ideas could be surveyed at a glance? And specific papers found like signposts on a path?
My approach was to map research as abstracted "threads" of progress: interleaving timelines of ideas as they are mixed and advanced from paper to paper. I sought to distill this simplified but foundationally meaningful structure from the citation network—the graph of papers connected by their citations and references. This network is extremely complex, with typically hundreds and sometimes thousands of connections leading to and from each paper. To extract the threads of progress, I use a natural language processing algorithm to identify keywords in each paper title. I posit these would signal key ideas in each paper. For each keyword, I create a subgraph from the citation network of papers whose titles contain it. Each connected component in a keyword subgraph is collapsed into an undirected path of papers ordered by publication year. This "keyword line" is an abstracted thread of progress. The keyword lines are finally visualized as colorful paths drawn through titles, much like a subway map. This map can be interactively explored by selecting focal keywords and expanding the network around promising papers.
Thanks to all the participants and to our winners! Special thanks to the project team at NASA Langley Center for supporting this competition!